Opinions probably differ, for example, on John Backus's paper "Can programming be liberated from the Von Neumann style?" Many fans of functional programming would say the answer is yes, but Backus himself expressed less enthusiasm in interviews later in his life.
I think the important point, though, is that academic papers and newspaper articles are not the same, and titles in the form of questions function differently in the two domains. Journalists tend to use titles like these to dissemble and sensationalize. When academics use these kinds of titles for peer-reviewed articles, it's because they really are asking an honest question. Backus was doing it in his paper. The authors of this paper are doing the same. They end the paper by re-iterating the question before launching into a discussion of the limitations that prevent them from reaching any firm conclusions on the answer to this question.
1) Yoshua's reputation would take a hit if this paper were bullshit, so he has extrinsic motivation to make it good 2) Yoshua has enough experience in the field to know what is going on in the field, you don't have to ask if he forgot about a certain architecture or the work of a certain research group which would contradict his findings-- if such work exists and is credible, it is very likely to be discussed in the paper. 3) This test answers something a leader in the field thinks is important enough for them to work on, else he wouldn't be involved.
Also note, the poster said the paper shouldn't be taken lightly. That doesn't mean we need to take it blindly. It only means we cannot dismiss it out of hand, if we have a different view we would need substantive arguments to defend our view.
I've overturned the field leader several times in science, but that's only because I acknowledged what they got right and that they were indeed the person who got it right.
no, that would be a grievous mistake on an anonymous site.
You will need to do that anyway, no matter if Yoshua is on the paper, or not. I understand that people have limited bandwidth, and so they need shortcuts, and they need to justify these shortcuts to themselves somehow (of course the justifications are nonsense). Maybe AI will help here.
Emphasis on not necessarily.
>> The main conclusion is that RNN class networks can be trained as efficiently as modern alternatives but the resulting performance is only competitive at small scale.
Shouldn't the conclusion be "the resulting competitive performance has only been confirmed at small scale"?
"Interesting work on reviving RNNs. https://arxiv.org/abs/2410.01201 -- in general the fact that there are many recent architectures coming from different directions that roughly match Transformers is proof that architectures aren't fundamentally important in the curve-fitting paradigm (aka deep learning)
Curve-fitting is about embedding a dataset on a curve. The critical factor is the dataset, not the specific hard-coded bells and whistles that constrain the curve's shape. As long as your curve is sufficiently expressive all architectures will converge to the same performance in the large-data regime."
I haven't fully ingested the paper yet, but it looks like it's focused more on compute optimization than the size of the dataset:
> ... and (2) are fully parallelizable during training (175x faster for a sequence of length 512
Even if many types of architectures converge to the same loss over time, finding the one that converges the fastest is quite valuable given the cost of running GPU's at scale.
This! Not just fastest but with the lowest resources in total.
Fully connected neural networks are universal functions. Technically we don’t need anything but a FNN, but memory requirements and speed would be abysmal far beyond the realm of practicality.
(Summary: quantum computing is unlikely to help.)
There is no known quantum algorithm that can compute the result of a fully-connected neural network exponentially faster than classical computers can. QCs have a known exponential advantage over classical computers only for a very limited class of problems, mostly related to the Quantum Fourier Transform.
Animal brains have little to nothing in common to artifical neural networks. There is no reason whatsoever to think that there is any relation between the complexity class of brain functions and ANN inference.
And the hypothesized (and still wildly speculative) quantum behaviors happening in the animal brain are at the level of the behavior of individual neurons, not of the network connections between neurons. So even if there is some kind of quantum computation happening, it's happening in individual neurons, not at the network level, and that would only go to show even more that animal brains are profoundly different from ANNs.
Not to him, he runs the ARC challenge. He wants a new approach entirely. Something capable of few-shot learning out of distribution patterns .... somehow
On the other hand, while "As long as your curve is sufficiently expressive all architectures will converge to the same performance in the large-data regime." is true, a sufficiently expressive mechanism may not be computationally or memory efficient. As both are constraints on what you can actually build, it's not whether the architecture can produce the result, but whether a feasible/practical instantiation of that architecture can produce the result.
You may be referring to Aidan Gomez (CEO of Cohere and contributor to the transformer architecture) during his Machine Learning Street Talk podcast interview. I agree, if as much attention had been put towards the RNN during the initial transformer hype, we may have very well seen these advancements earlier.
(Somewhat) fun and (somewhat) related fact: there's a whole cottage industry of "is all you need" papers https://arxiv.org/search/?query=%22is+all+you+need%22&search...
Tech just happens to be most on display at the moment - because tech people are building the tools and the parameters and the infrastructure handling all our interactions.
I could spam we are the stochastic parrots after all, yet one more time.
Which seems closer to true?
For example when CNNs took over computer vision that wasn't because they were doing something that dense networks couldn't do. It was because they removed a lot of edges that didn't really matter, allowing us to spend our training budget on deeper networks. Similarly transformers are great because they allow us to train gigantic networks somewhat efficiently. And this paper finds that if we make RNNs a lot faster to train they are actually pretty good. Training speed and efficiency remains the big bottleneck, not the actual expressiveness of the architecture
Some links if interested:
[1] https://gpt3experiments.substack.com/p/understanding-neural-...
[2] https://gpt3experiments.substack.com/p/building-a-vector-dat...
What the RNN must be doing reminds me of "sliding window attention" --- the model learns how to partition its state between short- and long-range memories to minimize overall loss. The two approaches seem related, perhaps even equivalent up to implementation details.
How do you encode arbitrarily long positions, anyway?
I think probably future NNs will be maybe more adaptive than this perhaps where some Perceptrons use sine wave functions, or other kinds of math functions, beyond just linear "y=mx+b"
It's astounding that we DID get the emergent intelligence from just doing this "curve fitting" onto "lines" rather than actual "curves".
Ax = y
Adding another layer is just multiplying a different set of weights times the output of the first, so
B(Ax)= y
If you remember your linear algebra course, you might see the problem: that can be simplified
(BA)x = y
Cx = y
Completely indistinguishable from a single layer, thus only capable of modeling linear relationships.
To prevent this collapse, a non linear function must be introduced between each layer.
But the entire NN itself (Perceptron ones, which most LLMs are) is still completely using nothing but linearity to store all the knowledge from the training process. All the weights are just an 'm' in the basic line equation 'y=m*x+b'. The entire training process does nothing but adjust a bunch of slopes of a bunch of lines. It's totally linear. No non-linearity at all.
> nothing but linearity
No, if you have non linearities, the NN itself is not linear. The non linearities are not there primarily to keep the outputs in a given range, though that's important, too.
Precisely what the `Activation Function` does is to squash an output into a range (normally below one, like tanh). That's the only non-linearity I'm aware of. What other non-linearities are there?
All the training does is adjust linear weights tho, like I said. All the training is doing is adjusting the slopes of lines.
This isn't the primary purpose of the activation function, and in fact it's not even necessary. For example see ReLU (probably the most common activation function), leaky ReLU, or for a sillier example: https://youtu.be/Ae9EKCyI1xU?si=KgjhMrOsFEVo2yCe
> Sure there's a squashing function on the output to keep it in a range from 0 to 1 but that's done BECAUSE we're just adding up stuff.
It's not because you're "adding up stuff", there is specific mathematical or statistical reason why it is used. For neural networks it's there to stop your multi layer network collapsing to a single layer one (i.e. a linear algebra reason). You can choose whatever function you want, for hidden layers tanh generally isn't used anymore, it's usually some variant of a ReLU. In fact Leaky ReLUs are very commonly used so OP isn't changing the subject.
If you define a "perceptron" (`g(Wx+b)` and `W` is a `Px1` matrix) and train it as a logistic regression model then you want `g` to be sigmoid. Its purpose is to ensure that the output can be interpreted as a probability (given that use the correct statistical loss), which means squashing the number. The inverse isn't true, if I take random numbers from the internet and squash them to `[0,1]` I don't go call them probabilities.
> and not only is it's PRIMARY function to squash a number, that's it's ONLY function.
Squashing the number isn't the reason, it's the side effect. And even then, I just said that not all activation functions squash numbers.
> All the training does is adjust linear weights tho, like I said.
Not sure what your point is. What is a "linear weight"?
We call layers of the form `g(Wx+b)` "linear" layers but that's an abused term, if g() is non-linear then the output is not linear. Who cares if the inner term `Wx + b` is linear? With enough of these layers you can approximate fairly complicated functions. If you're arguing as to whether there is a better fundamental building block then that is another discussion.
In the context of discussing linearity v.s. non-linearity adding the word "linear" in front of "weight" is more clear, which is what my top level post on this thread was all about too.
It's astounding to me (and everyone else who's being honest) that LLMs can accomplish what they do when it's only linear "factors" (i.e. weights) that are all that's required to be adjusted during training, to achieve genuine reasoning. During training we're not [normally] adjusting any parameters or weights on any non-linear functions. I include the caveat "normally", because I'm speaking of the basic Perceptron NN using a squashing-type activation function.
When such basic perceptrons are scaled enormously, it becomes less surprising that they can achieve some level of 'genuine reasoning' (e.g., accurate next-word prediction), since the goal with such networks at the end of the day is just function approximation. What is more surprising to me is how we found ways to train such models i.e., advances in hardware accelerators, combined with massive data, which are factors just as significant in my opinion.
If you want to say reasoning and token prediction are just the same thing at scale you can say that, but I don't fall into that camp. I think there's MUCH more to learn, and indeed a new field of math or even physics that we haven't even discovered yet. Like a step change in mathematical understanding analogous to the invention of Calculus.
Technically the output is still what a statistician would call “linear in the parameters”, but due to the universal approximation theorem it can approximate any non-linear function.
https://stats.stackexchange.com/questions/275358/why-is-incr...
"only" is doing a lot work here because that non-linearity is enough to vastly expand the landscape of functions that an NN can approximate. If the NN was linear, you could greatly simplify the computational needs of the whole thing (as was implied by another commenter above) but you'd also not get a GPT out of it.
That would still be linear. And the result would be that despite squashing, no matter how many layers a model had, it could only fit linear problems. Which can always be fit with a single layer, i.e. single matrix.
So nobody does that.
The nonlinearity doesn't just squash some inputs. But create a new rich feature, decision making. That's because on one side of a threshold y gets converted very differently than another. I.e if y > 0, y' = y, otherwise y = 0.
Now you have a discontinuity in behavior, you have a decision.
Multiple layers making decisions can do far more than a linear layer. They can fit any continuous function (or any function with a finite number of discontinuities) arbitrarily well.
Non-linearities add a fundamental new feature. You can think of that features as being able to make decisions around the non-linear function's decision points.
---
If you need to prove this to yourself with a simple example, try to create an XOR gate with this function:
y = w1 * x1 + w2 * x2 + b.
You are welcome to linearly squash the output, i.e. y' = y * w3, for whatever small w3 you like. It won't help.
Layers with non-linear transformations are layers of decision makers.
Layers of linear transforms are just unnecessarily long ways of writing a single linear transform. Even with linear "squashing".
But I still find it counter-intuitive that it's not common practice in standard LLM NNs to have a trainable parameter that in some way directly "tunes" whatever Activation Function is being applied on EACH output.
For example I almost started experimenting with trigonometric activation functions in a custom NN where the phase angle would be adjusted, inspired by Fourier Series. I can envision a type of NN where every model "weight" is actually a frequency component, because Fourier Series can represent any arbitrary function in this way. There has of course already been similar research done by others along these lines.
That's not the main point even though it probably helps. As OkayPhysicist said above, without a nonlinearity, you could collapse all the weight matrices into a single matrix. If you have 2 layers (same size, for simplicity) described by weight matrices A and B, you could multiply them and get C, which you could use for inference.
Now, you can do this same trick not only with 2 layers but 100 million, all collapsing into a single matrix after multiplication. If the nonlinearities weren't there, the effective information content of the whole NN would collapse into that of a single-layer NN.
You're curious about whether there is gain in parameterising activation functions and learning them instead, or rather, why it's not used much in practice. That's an interesting and curious academic question, and it seems like you're already experimenting with trying out your own kinds of activation functions. However, people in this thread (including myself) wanted to clarify some perceived misunderstandings you had about nonlinearities and "why" they are used in DNNs. Or how "squashing functions" is a misnomer because `g(x) = x/1000` doesn't introduce any nonlinearities. Yet you continue to fixate and double down on your knowledge of "what" a tanh is, and even that is incorrect.
ReLU enables this by being nonlinear in a simple way, specifically by outputting zero for negative inputs, so each linear unit can then limit its contribution to a portion of the output curve.
(This is a lot easier to see on a whiteboard!)
I’ll just reiterate that the single “technical” (whatever that means) nonlinearity in ReLU is exactly what lets a layer approximate any continuous[*] function.
[*] May have forgotten some more adjectives here needed for full precision.
Followed by "in some sense it's [ReLU] still even MORE linear than tanh or sigmoid functions are". There's no way you misunderstood that sentence, or took it as my "definition" of linearity...so I guess you just wanted to reaffirm I was correct, again, so thanks.
So, for XOR, (x, y) -> (x, y, xy), and it becomes trivial for a linear NN to solve.
Architectures like Mamba have a linear recurrent state space system as their core, so even though you need a nonlinearity somewhere, it doesn't need to be pervasive. And linear recurrent networks are surprisingly powerful (https://arxiv.org/abs/2303.06349, https://arxiv.org/abs/1802.03308).
In Ye Olden days (the 90’s) we used to approximate non-linear models using splines or seperate slopes models - fit by hand. They were still linear, but with the right choice of splines you could approximate a non-linear model to whatever degree of accuracy you wanted.
Neural networks “just” do this automatically, and faster.
It's an interesting concept to think of how NNs might be able to exploit this effect in some way based on straight lines in the weights, because a very small number of points can identify avery precise and smooth curves, where directions on the curve might equate to Semantic Space Vectors.
Another thing about the architecture is we inherently bias it with the way we structure the data. For instance, take a dataset of (car) traffic patterns. If you only track the date as a feature, you miss that some events follow not just the day-of-year pattern but also holiday patterns. You could learn this with deep learning with enough data, but if we bake it into the dataset, you can build a model on it _much_ simpler and faster.
So, architecture matters. Data/feature representation matters.
I think you need a hidden layer. I’ve never seen a universal approximation theorem for a single layer network.
I have almost the opposite take. We've had a lot of datasets for ages, but all the progress in the last decade has come from advances how curves are architected and fit to the dataset (including applying more computing power).
Maybe there's some theoretical sense in which older models could have solved newer problems just as well if only we applied 1000000x the computing power, so the new models are 'just' an optimisation, but that's like dismissing the importance of complexity analysis in algorithm design, and thus insisting that bogosort and quicksort are equivalent.
When you start layering in normalisation techniques to minimise overfitting, and especially once you start thinking about more agentic architectures (eg. Deep Q Learning, some of the search space design going into OpenAI's o1), then I don't think the just-an-optimisation perspective can hold much water at all - more computing power simply couldn't solve those problems with older architectures.
However it's still an interesting observation that many architectures can arrive at the same performance (even though the training requirements are different).
Naively, you wouldn't expect eg 'x -> a * x + b' to fit the same data as 'x -> a * sin x + b' about equally well. But that's an observation from low dimensions. It seems once you add enough parameters, the exact model doesn't matter too much for practical expressiveness.
I'm faintly reminded of the Church-Turing Thesis; the differences between different computing architectures are both 'real' but also 'just an optimisation'.
> When you start layering in normalisation techniques to minimise overfitting, and especially once you start thinking about more agentic architectures (eg. Deep Q Learning, some of the search space design going into OpenAI's o1), then I don't think the just-an-optimisation perspective can hold much water at all - more computing power simply couldn't solve those problems with older architectures.
You are right, these normalisation techniques help you economise on training data, not just on compute. Some of these techniques can be done independent of the model, eg augmenting your training data with noise. But some others are very model dependent.
I'm not sure how the 'agentic' approaches fit here.
I, a nave, expected this.
Is multiplication versus sine in the analogy hiding it, perhaps?
I've always pictured it as just "needing to learn" the function terms and the function guts are an abstraction that is learned.
Might just be because I'm a physics dropout with a bunch of whacky half-remembered probably-wrong stuff about how any function can be approximated by ex. fourier series.
In my example, a and b were the parameters. The kinds of data you can approximate well with a simple sine wave and the kinds of data you can approximate with a straight line are rather different.
Training your neural net only fiddles with the parameters like a and b. It doesn't do anything about the shape of the function. It doesn't change sine into multiplication etc.
> [...] about how any function can be approximated by ex. fourier series.
Fourier series are an interesting example to bring up! I think I see what you mean.
In theory they work well to approximate any function over either a periodic domain or some finite interval. But unless you take special care, when you apply Fourier analysis naively it becomes extremely sensitive to errors in the phase parameters.
(Special care could eg be done by hacking up your input domain into 'boxes'. That works well for eg audio or video compression, but gives up on any model generalisation between 'boxes', especially for what would happen in a later box.)
Another interesting example is Taylor series. For many simple functions Taylor series are great, but for even moderately complicated ones you need to be careful. See eg how the Taylor serious for the logarithm around x=1 works well, but if you tried it around x=0, you are in for a bad time.
The interesting observation isn't just that there are multiple universal approximators, but that at high enough parameter count, they seem to perform about equally well in how good they are at approximating in practice (but differ in how well they can be trained).
It definitely can. The output will always be piecewise linear (with ReLU), but the overall shape can change completely.
Big AI minimizes that problem by using more data. So much data that the model often only sees each data point once and overfitting is unlikely.
Not the shape of its graph when you draw it.
Another way to look at it is that like you say, it was an old video but there has been progress since though we had large datasets when it came out by its own definition
I'm sure there are optimizations from the model shape as well, but I don't think that running the best algorithms we have today with hardware from five-ten years ago would have worked in any reasonable amount of time/money.
We have GPT-4 (or at least 3.5) tier performance in these much smaller models now. If we teleported back in time it may have been possible to build
I should also mention that the idea itself of using GPUs for compute and then specifically for AI training was an innovation. And the idea that simply scaling up was going to be worth the investment is another major innovation. It's not just the existence of the compute power, it's the application to NN training tasks that got us here.
Here[0] is an older OpenAI post about this very topic. They estimate that between 2012 and 2018, the compute power used for training the SotA models at those times increased roughly 300,000 times, doubling every ~3.5 months.
From theory the answer to the question should be "yes", they are Turing complete.
The real question is about how to train them, and the paper is about that.
In more practical terms, you would imagine that an advanced model contains some semblance of a CPU to be able to truly reason. Given that CPUs can be all NAND gates (which take 2 neurons to represent), and are structured in a recurrent way, you fundamentally have to rethink how to train such a network, because backprop obviously won't work to capture things like binary decision points.
If you were to search for billions of parameters by brute force, you literally could not do it in the lifespan of the universe.
A neural network is differentiable, meaning you can take the derivative of it. You train the parameters by taking finding gradient with respect to each parameter, and going in the opposite direction. Hence the name of the popular algorithm, gradient descent.
Gradient descent isn't the only way to do this. Evolutionary techniques can explore impossibly large, non-linear problem spaces.
Being able to define any kind of fitness function you want is sort of like a super power. You don't have to think in such constrained ways down this path.
Biology is biology and has its constraints. Doesn't necessarily mean a biologically plausible optimizer would be the most efficient or correct way in silicon.
>If the thing we want to build is not realizable with this technique, why can't we move on from it?
All the biologically plausible optimizers we've fiddled with (and we've fiddled with quite a lot) just work (results wise) like gradient descent but worse. We've not "moved on" because gradient descent is and continues to be better.
>Evolutionary techniques can explore impossibly large, non-linear problem spaces.
Sure, with billions of years (and millions of concurrent experiments) on the table.
1: https://www.sciencedirect.com/science/article/pii/0893965991...
2: https://en.wikipedia.org/wiki/Rice%27s_theorem?useskin=vecto...
> RNNs are particularly suitable for sequence modelling settings such as those involving time series, natural language processing, and other sequential tasks where context from previous steps informs the current prediction.
I would like to draw an analogy to digital signal processing. If you think of the recurrent-style architectures as IIR filters and feedforward-only architectures as FIR filters, you will likely find many parallels.
The most obvious to me being that IIR filters typically require far fewer elements to produce the same response as an equivalent FIR filter. Granted, the FIR filter is often easier to implement/control/measure in practical terms (fixed-point arithmetic hardware == ML architectures that can run on GPUs).
I don't think we get to the exponential scary part of AI without some fundamentally recurrent architecture. I think things like LSTM are kind of an in-between hack in this DSP analogy - You could look at it as FIR with dynamic coefficients. Neuromorphic approaches seem like the best long term bet to me in terms of efficiency.
The most compelling and obvious one to me is hardware purpose-built to simulate spiking neural networks. In the happy case, SNNs are extremely efficient. Basically consuming no energy. You could fool yourself into thinking we can just do this on the CPU due to the sparsity of activations. I think there is even a set of problems this works well for. But, in the unhappy cases SNNs are impossible to simulate on existing hardware. Neuronal avalanches follow power law distribution and meaningfully-large ones would require very clever techniques to simulate with any reasonable fidelity.
> the system isn't just simulating neurons but involves a variety of methods and interactions across "agents" or sub-systems.
I think the line between "neuron" and "agent" starts to get blurry in this arena.
Secondly how do we get to claim that a particular thing is neuromorphic when we have such a rudimentary understanding of how a biological brain works or how it generates things like a model of the world, understanding of self etc etc.
Estimates put training of gpt4 at something like 2500 gpu years to train, over about 10000 gpus. 20 years would be a big improvement.
We have NO idea how the brain produces intelligence, and as long as that doesn't change, "neuromorphic" is merely a marketing term, like Neurotypical, Neurodivergent, Neurodiverse, Neuroethics, Neuroeconomics, Neuromarketing, Neurolaw, Neurosecurity, Neurotheology, Neuro-Linguistic Programming: the "neuro-" prefix is suggesting a deep scientific insight to fool the audience. There is no hope of us cracking the question of how the human brain produces high-level intelligence in the next decade or so.
Neuromorphic does work for some special purpose applications.
/way out of my area of expertise here
I would highly recommend it to people who love a good "near future" scifi book.
I’ve been thinking the same for a while, but I’m starting to wonder if giant context windows are good enough to get us there. I think recurrency is more neuromorphic, and possibly important in the longer run, but maybe not required for SI.
I’m also just a layman with just a surface level understanding of these things, so I may be completely ignorant and wrong.
FIR filters are way simpler to design and can capture memory without hacks.
What LLMs have shown both Neuroscience and Computer Science is that reasoning is a mechanical process (or can be simulated by mechanical processes) and is not purely associated only with consciousness.
https://arxiv.org/html/2409.13373v1
This is a basic form of reasoning, to plan out the steps needed to execute something.
It's like I'm saying a house is made of bricks. You can build a house of any shape out of bricks. But once bricks have been invented you can build houses. The LLM "reasoning" that even existed as early as GPT3.5 was the "brick" with which highly intelligent agents can be built out of, with no further "breakthroughs" being required.
The basic Transformer Architecture was enough and already has the magical ingredient of reasoning. The rest is just a matter of prompt engineering.
The prompt engineering is the real reasoning, provided by the human.
My point is computers already follow algorithms, and algorithms contain reasoning; but the computers are not reasoning themselves. At least, not yet!
I think a "granule" of "reasoning" happens at each inference, and you think there is no reasoning in a single inference. To discuss it further would be a game of whose definition of any given word is correct.
This is obvious when one considers the connections between Transformers, RNNs, Hopfield networks and the Ising model, a model from statistical mechanics which is solved by calculating the partition function.
This interpretation provides us with some very powerful tools that are commonplace in math and physics but which are not talked about in CS & ML.
I'm working on a startup http://traceoid.ai which takes this exact view. Our approach enables faster training and inference, interpretability and also scalable energy-based models, the Holy Grail of machine learning.
Join the discord https://discord.com/invite/mr9TAhpyBW or follow me on twitter https://twitter.com/adamnemecek1
class MinGRU(nn.Module):
def __init__(self, token_size, hidden_state_size):
self.token_to_proposal = nn.Linear(token_size, hidden_size)
self.token_to_mix_factors = nn.Linear(token_size, hidden_size)
def forward(self, previous_hidden_state, current_token):
proposed_hidden_state = self.token_to_proposal(current_token)
mix_factors = torch.sigmoid(self.token_to_mix_factors(current_token))
return torch.lerp(proposed_hidden_state, previous_hidden_state, mix_factors)
The fact that this is competitive with transformers and state-space models in their small-scale experiments is gratifying to the "best PRs are the ones that delete code" side of me. That said, we won't know for sure if this is a capital-B Breakthrough until someone tries scaling it up to parameter and data counts comparable to SOTA models.
One detail I found really interesting is that they seem to do all their calculations in log-space, according to the Appendix. They say it's for numerical stability, which is curious to me—I'm not sure I have a good intuition for why running everything in log-space makes the model more stable. Is it because they removed the tanh from the output, making it possible for values to explode if calculations are done in linear space?
EDIT: Another thought—it's kind of fascinating that this sort of sequence modeling works at all. It's like if I gave you all the pages of a book individually torn out and in a random order, and asked you to try to make a vector representation for each page as well as instructions for how to mix that vector with the vector representing all previous pages — except you have zero knowledge of those previous pages. Then, I take all your page vectors, sequentially mix them together in-order, and grade you based on how good of a whole-book summary the final vector represents. Wild stuff.
FURTHER EDIT: Yet another thought—right now, they're just using two dense linear layers to transform the token into the proposed hidden state and the lerp mix factors. I'm curious what would happen if you made those transforms MLPs instead of singular linear layers.
Here's why.
A user of an LLM might give the model some long text and then say "Translate this into German please". A Transformer can look back at its whole history. But what is an RNN to do? While the length of its context is unlimited, the amount of information the model retains about it is bounded by whatever is in its hidden state at any given time.
Relevant: https://arxiv.org/abs/2402.01032
Is there a way to prove this? One potential caveat that comes to mind for me is that perhaps the action of lerping between the old state and the new could be used by the model to perform semantically meaningful transformations on the old state. I guess in my mind it just doesn't seem obvious that the hidden state is necessarily a collection of "redundant information" — perhaps the information is culled/distilled the further along in the sequence you go? There will always be some redundancy, sure, but I don't think that such redundancy necessarily means we have to use superlinear methods like attention.
The information cost of making the RNN state way bigger is high when done naively, but maybe someone can figure out a clever way to avoid storing full hidden states in memory during training or big improvements in hardware could make memory use less of a bottleneck.
Which isn't necessary. If you say "translate the following to german." Instead, all it needs is to remember the task at hand and a much smaller amount of recent input. Well, and the ability to output in parallel with processing input.
A model can decide to forget something that turns out to be important for some future prediction. A human can go back and re-read/listen etc, A transformer is always re-reading but a RNN can't and is fucked.
There is a recent paper from Meta that propose a way to train a model to backtrack its generation to improve generation alignment [0].
But it's trained on translations, rather than the whole Internet.
Consider the flood fill algorithm or union-find algorithm, which feels magical upon first exposure.
https://en.wikipedia.org/wiki/Hoshen%E2%80%93Kopelman_algori...
Having 2 passes can enable so much more than a single pass.
Another alternative could be to have a first pass make notes in a separate buffer while parsing the input. The bandwidth of the note taking and reading can be much much lower than that required for fetching the billions of parameters.
This is no different than a transformer, which, after all, is bound by a finite state, just organized in a different manner.
It's not just a matter of organizing things differently. Suppose your network dimension and sequence length are both X.
Then your memory usage (per layer) will be O(X^2), while your training update cost will be O(X^3). That's for both Transformers and RNNs.
However, at the end of the sequence, a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers.
16N bits as hard limit, but more realistically, about 2N bits or less of useful information probably.
You'd need to grow the network dimension in proportion to the maximum sequence length just to avoid the information theoretical limit.
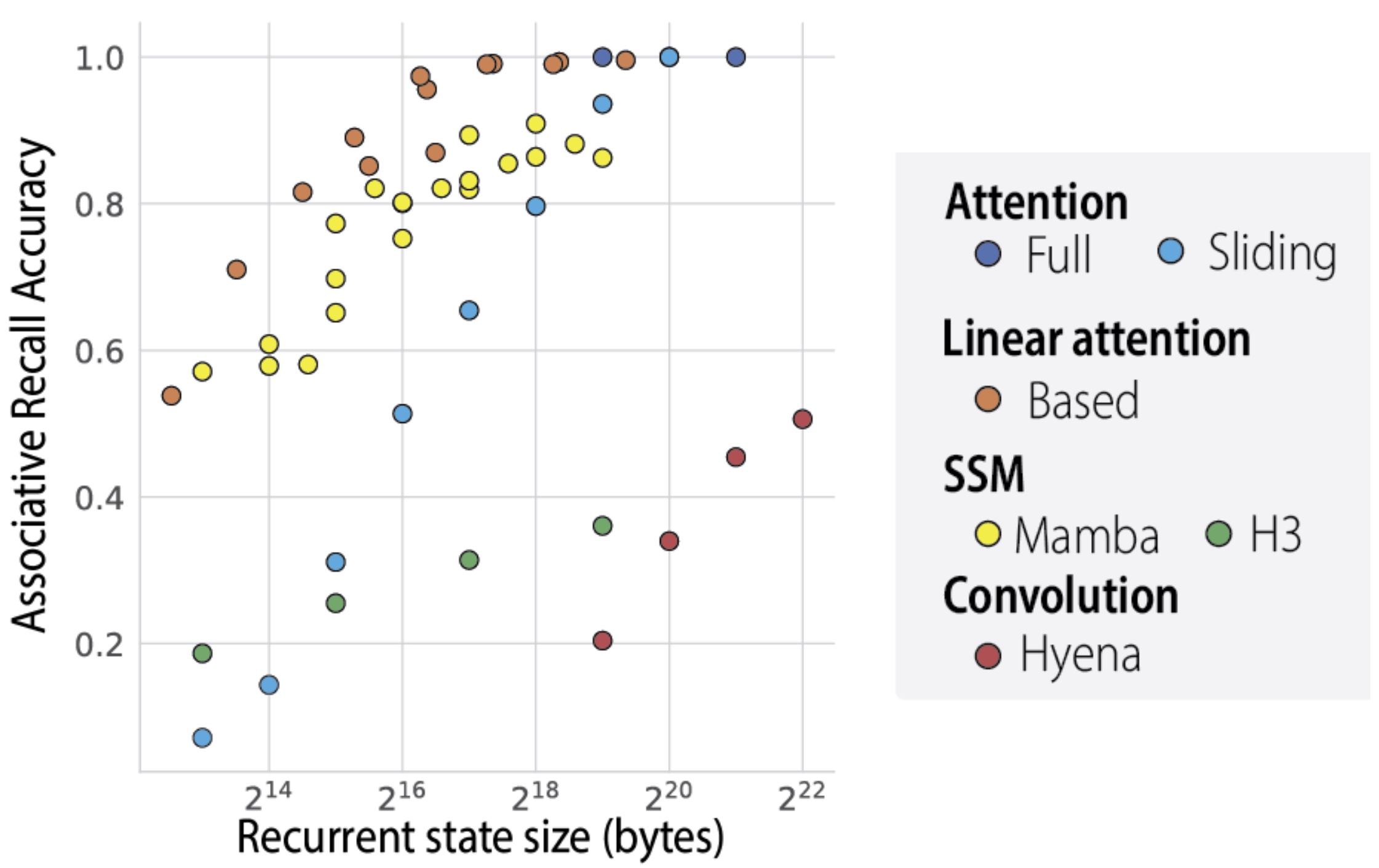
(this is from the Based paper: https://arxiv.org/pdf/2402.18668)
Are you griping about my writing O(X^2) above instead of precisely 2X^2, like this paper? The latter implies the former.
> So a sufficiently sized RNN could have the same state capacity as a transformer.
Does this contradict anything I've said? If you increase the size of the RNN, while keeping the Transformer fixed, you can match their recurrent state sizes (if you don't run out of RAM or funding)
> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
The thing is RNN can look back infinitely if you don't exceed the state capacity. For transformers the state it is defined semi-implicitly (you can change the hidden dims but you cannot extend the look back; ignoring transformer-xl et al.) defined by the amount of tokens, for an RNN it's defined explicitly by the state size.
The big-O here is irrelevant for the architectures since it's all in the configuration & implementation of the model; i.e. there is no relevant asymptote to compare.
As an aside this was what was shown in the based paper, the fact that you can have a continuity of state (as with RNN) while have the same associative recall capability as a transformer (the main downfall of recurrent methods at that point).
?!
NNs are like any other algorithm in this regard. Heck, look at the bottom of page 2 of the Were RNNs All We Needed paper. It has big-O notation there and elsewhere.
> I was responding to
>> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
In the BASED paper, in Eq. 10, sizeof(s) = 2dN. But I defined d = N = X above. Ergo, sizeof(s) = 2X^2 = O(X^2).
For minGRU, sizeof(s) = d. Ergo, sizeof(s) = X = O(X).
Transformers do have O(N^2) time & memory complexity, and Based/RNN/SSM {O(N) time, O(1) mem}, with respect to sequence length if that's what you mean. The point is it doesn't really give an indication of quality.
We can choose our constant arbitrarily so the big-O you've stated only indicates memory/time-complexity not 'look-back' ability relevant to any task. If you input the entire sequence N times into an RNN, you also have perfect recall with O(N^2) but it's not exactly an efficient use of our resources.
Ideally our state memory is maximally utilized, this is the case for RNNs in the limit (although likely oversubscribed) but is not the case for transformers. The holy grail is to have an input-dependent state-size, however that is quite difficult.
An AI Winter is not a great an idea, but an AI Autumn may be beneficial.
Just have no major AI conferences for ‘25, perhaps only accept really high tier literature reviews.
I'm honestly a bit envious of future engineers who will be tackling these kinds of problems with a 100-line Jupyter notebook on a laptop years from now. If we discovered the right method or algorithm for these long-horizon problems, a 2B-parameter model might even outperform current models on everything except short, extreme reasoning problems.
The only solution I've ever considered for this is expanding a model's dimensionality over time, rather than focusing on perfect weights. The higher dimensionality you can provide to a model, the greater its theoretical storage capacity. This could resemble a two-layer model—one layer acting as a superposition of multiple ideal points, and the other layer knowing how to use them.
When you think about the loss landscape, imagine it with many minima for a given task. If we could create a method that navigates these minima by reconfiguring the model when needed, we could theoretically develop a single model with near-infinite local minima—and therefore, higher-dimensional memory. This may sound wild, but consider the fact that the human brain potentially creates and disconnects thousands of new connections in a single day. Could it be that these connections steer our internal loss landscape between different minima we need throughout the day?
Models that change size as needed have been experimented with, but they are either too inefficient or difficult to optimize at a limited power budget. However, I agree that they are likely what is needed if we want to continue to scale upward in size.
I suspect the real bottleneck is a breakthrough in training itself. Backpropagation loss is too simplistic to optimize our current models perfectly, let alone future larger ones. But there is no guarantee a better alternative exists which may create a fixed limit to current ML approaches.
Mine worked, but it was very simple and dog slow, running on my old laptop. Nothing was ever going to run fast on that thing, but I remember my RNN being substantially slower than a feed-forward network would have been.
I was so confident that this was dead technology -- an academic curiosity from the 1980s and 1990s. It was bizarre to see how quickly that changed.
BPTT was their problem
In 2016 my team from Salesforce Research published our work on the Quasi-Recurrent Neural Network[1] (QRNN). The QRNN variants we describe are near identical (minGRU) or highly similar (minLSTM) to the work here.
The QRNN was used, many years ago now, in the first version of Baidu's speech recognition system (Deep Voice [6]) and as part of Google's handwriting recognition system in Gboard[5] (2019).
Even if there are expressivity trade-offs when using parallelizable RNNs they've shown historically they can work well and are low resource and incredibly fast. Very few of the possibilities regarding distillation, hardware optimization, etc, have been explored.
Even if you need "exact" recall, various works have shown that even a single layer of attention with a parallelizable RNN can yield strong results. Distillation down to such a model is quite promising.
Other recent fast RNN variants such as the RWKV, S4, Mamba et al. include citations to QRNN (2016) and SRU (2017) for a richer history + better context.
The SRU work has also had additions in recent years (SRU++), doing well in speech recognition and LM tasks where they found similar speed benefits over Transformers.
I note this primarily as the more data points, especially when strongly relevant, the better positioned the research is. A number of the "new" findings from this paper have been previously explored - and do certainly show promise! This makes sure we're asking new questions with new insights (with all the benefit of additional research from ~8 years ago) versus missing the work from those earlier.
[1] QRNN paper: https://arxiv.org/abs/1611.01576
[2] SRU paper: https://arxiv.org/abs/1709.02755
[3]: SRU++ for speech recognition: https://arxiv.org/abs/2110.05571
[4]: SRU++ for language modeling: https://arxiv.org/abs/2102.12459
[5]: https://research.google/blog/rnn-based-handwriting-recogniti...
Compare with one human brain. Far more sophisticated, even beyond our knowledge. What does it take to power it for a day? Some vegetables and rice. Still fine for a while if you supply pure junk food -- it'll still perform.
Clearly we have a long, long way to go in terms of the energy efficiency of AI approaches. Our so-called neural nets clearly don't resemble the energy efficiency of actual biological neurons.
Maybe the future of AI is in organic neurons?
Based on my own experience, I would struggle to generate that much text without fries and a drink.
[1] https://www.theverge.com/24066646/ai-electricity-energy-watt...
But yes, food energy could be useful for AI. A little dystopian potentially too, if you think about it. Like DARPA's EATR robot, able to run on plant biomass (although potentially animal biomass too, including human remains):
https://en.wikipedia.org/wiki/Energetically_Autonomous_Tacti...
We were able to build generators that could replicate any dataset they were trained on, and would produce unique deviations, but match the statistical underpinnings of the original datasets.
https://medium.com/capital-one-tech/why-you-dont-necessarily...
We built several text generators for bots that similarly had very good results. The introduction of the transformer improved the speed and reduced the training / data requirements, but honestly the accuracy changed minimal.
Do we have solutions for these two problems now?
RNN are constantly updating and overwriting their memory. It means they need to be able to predict what is going to be useful in order to store it for later.
This is a massive advantage for Transformers in interactive use cases like in ChatGPT. You give it context and ask questions in multiple turns. Which part of the context was important for a given question only becomes known later in the token sequence.
To be more precise, I should say it's an advantage of Attention-based models, because there are also hybrid models successfully mixing both approaches, like Jamba.
A great thing about RNNs is they can easily fork the state and generate trees, it would be possible to backtrack and work on combinatorial search problems.
Also easier to cache demonstrations for free in the initial state, a model that has seen lots of data is not using more memory than a model starting from scratch.
https://www.semanticscholar.org/paper/Long-Short-Term-Memory...
I find it interesting that this knowledge seems to be all but forgotten now. Back in the day, ca. 2014, LSTMs were all the rage, e.g. see:
I don't want to downplay the value of these models. Some people seem to be under the perception that transformers replaced or made them obsolete, which is faar from the truth.
I see this stuff everywhere online and it's often taught this way so I don't blame folks for repeating it, but I think it's likely promulgated by folks who don't train LSTMs with long contexts.
LSTMs do add something like a "skip-connection" (before that term was a thing) which helps deal with the catastrophic vanishing gradients you get from e.g. Jordan RNNs right from the jump.
However (!), while this stops us from seeing vanishing gradients after e.g. 10s or 100s of time-steps, when you start seeing multiple 1000s of tokens, the wheels start falling off. I saw this in my own research, training on amino acid sequences of 3,000 length led to a huge amount of instability. It was only after tokenizing the amino acid sequences (which was uncommon at the time) which got us down to ~1500 timesteps on average, did we start seeing stable losses at training. Check-out the ablation at [0].
You can think of ResNets by analogy. ResNets didn't "solve" vanishing gradients, there's a practical limit of the depth of networks, but it did go a long way towards dealing with it.
EDIT: I wanted to add, while I was trying to troubleshoot this for myself, it was super hard to find evidence online of why I was seeing instability. Everything pertaining to "vanishing gradients" and LSTMs were blog posts and pre-prints which just merrily repeated "LSTMs solve the problem of vanishing gradients". That made it hard for me, a junior PhD at the time, to suss out the fact that LSTMs do demonstrably and reliably suffer from vanishing gradients at longer contexts.
[0] https://academic.oup.com/bioinformatics/article/38/16/3958/6...
We haven't tried truncated BPTT, but we certainly should.
Funnily enough, we adopted AWD-LSTMs, Ranger21, and Mish in the paper I linked after I heard about them through the fast.ai community (we also trialled QRNNs for a bit too). fast.ai has been hugely influential in my work.
Recent comments from him have said that any architecture can achieve transformer accuracy and recall, but we have devoted energy to refining transformers, due to the early successes.
This is very clever and very interesting. The paper continuously calls it a "decade-old architecture," but in practice, it's still used massively, thanks to its simplicity in adapting to different domains. Placing it as a "competitor" to transformers is also not quite fully fair, as transformers and RNNs are not mutually exclusive, and there are many methods that merge them.
Improvement in RNNs is an improvement in a lot of other surprising places. A very interesting read.
It's obvious why the newest toy from openai can solve problems better mostly by just being allowed to "talk to itself" for a moment before starting the answer that human sees.
Given that, modern incarnation of RNN can be vastly cheaper than transformers provided that they can be trained.
Convolutional neural networks get more visual understanding by "reusing" their capacity across the area of the image. RNN's and transformers can have better understanding of a given problem by "reusing" their capacity to learn and infer across time (across steps of iterative process really).
When it comes to transformer architecture the attention is a red herring. It's just more or less arbitrary way to partition the network so it can be parallelized. The only bit of potential magic is with "shortcut" links between non adjacent layers that help propagate learning back through many layers.
Basically the optimal network is deep, dense (all neurons connect with all belonging to all preceding layers) that is ran in some form of recurrence.
But we don't have enough compute to train that. So we need to arbitrarily sever some connections so the whole thing is easier to parallelized. It really doesn't matter which unless we do in some obviously stupid way.
Actual inventive magic part of LLMs possibly happens in token and positional encoders.
Conceptually we already have parts of the model that are not learned: the architecture of the model itself.
Everything else is just details.
{kind=link}