Great work, looks amazing.
cut comes to mind as an example, slicing and dicing lines into fields quickly without a ton of copies isn't easy. Using Streaming.ByteString generally makes a huge difference, but it's extremely difficult to use unless you get can your mind to meld with the types it wants. Picking it up again months later takes some serious effort.
https://github.com/Gandalf-/coreutils/blob/master/Coreutils/...
There are libraries that handle it, but they probably have weird types, you can just use functions in the prelude to write a lot of these basic utilities.
For one thing, a "string" in Haskell by default is a linked list of unicode characters, so right out of the gate you've got big performance problems if you want to use strings. The exact way laziness is done also has serious performance consequences as well; when dealing with things as small as individual characters all the overhead looms large as a percentage basis. One of the major purposes of any of the several variants of ByteString is to bundle the bytes together, but that means you're back to dealing with chunks. Haskell does end up with a nice API that can abstract over the chunks but it still means you sometimes have to deal with chunks as chunks; if you turn them back into a normal Haskell "string" you lose all the performance advantages.
It can still come out fairly nice, but if you want performance it is definitely not just a matter of opening a file and pretending you've just got one big lazy string and you can just ignore all the details; some of the details still poke out.
The other advantage is just deferring IO. For instance in split or tee, you could decide that you need 500 output files and open all the handles together in order to pass them to another function that will consume them. I'd squint at someone who wrote `void process_fds(int fds[500]);`, but here it doesn't matter.
Strict to lazy is normally a rewrite.
Strict to lazy is normally a rewrite.
I have not found this to be the case with "mklink /h".
Would hardlinks help (would avoid multiple copies)?
I’m a very very novice “functional programmer” but on occasion I find problems that feel just ridiculous to implement FP style.
cut comes to mind as a difficult one. In C, you can just hop around the char buffer[] and drop nulls in place for fields, etc before printing. You could go that way a Data.Array Char, but that's hard to justify as functional.
You basicaly map one line of a stream to another with some filtering and joining. Do I miss the part where it's terribly slow and/or not doable in Haskell or something?
Same for all the remaining web standards.
C is simple enough to know what is going on, IMO.
For example:
numbers = [1, 2, 3, 4, 5]
squared_numbers = [num * num for num in numbers]
print(squared_numbers)
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
let squared_numbers: Vec<i32> = numbers.iter().map(|&num| num * num).collect();
println!("{:?}", squared_numbers);
}
#include <stdio.h>
int main() {
int numbers[] = {1, 2, 3, 4, 5};
int squared_numbers[5];
// Squaring each number
for (int i = 0; i < 5; i++) {
squared_numbers[i] = numbers[i] * numbers[i];
}
// Printing the squared numbers
printf("[");
for (int i = 0; i < 5; i++) {
printf("%d", squared_numbers[i]);
if (i < 4) printf(", ");
}
printf("]\n");
return 0;
}
What I am trying to say is that the C implementation is more straightforward, IMO.
There's no way that C implementation is easier to read than the Python one. There's no high-level abstraction going on there and the list comprehension reads like natural language.
I agree Rust often gets distracting with unwrapping and lifetime notation.
The example above may not highlight what I was trying to, however.
Perhaps Ada could work even better than C? It is verbose, yes, but you will immediately know what is going on.
My point is, that in my opinion verbosity is better than conciseness in cases of reference implementations.
C on the other hand forces handling too many low level details for a reference implementation IMO. Rust also isn't really good in that regard.
In a reference implementation what needs to be made explicit is the logic that needs to be implemented, rather than details like memory management. For that I would prefer something like Datalog instead.
I agree.
// Printing the squared numbers
printf("[");
for (int n = 5, *p = squared_numbers; --n >= 0; p++)
printf("%d%s", *p, n > 0 ? ", " : "]\n");
But n-->0 is prettier.
I noticed that they are about as long and complex as the C versions. In early C++/STL days part of the pitch was reimplementing core utils in a much more concise way. In wonder if the is a result of focusing on that application, or a coincidence of design decisions.
I know little about functional programming languages but I've always been interested in how languages like Ada and now Rust can help programmers write safer code. I'm curious what advantages a rewrite of a C/C++ app in a FP language provides and also what advantages a FP language brings in comparison to a language like Rust.
When I last looked 'dd' was significantly slower, though I did make it a bit closer a while back - https://jackson.dev/post/rust-coreutils-dd/
A lot of the Rust coreutils were written by people learning the language, and the code is often _more_ complicated than the corresponding code for the Unix utils. They don't seem to get enough experienced programmers fixing them up or usage for me to actually recommend anybody use them, but maybe that's changing.
I read your blog. Maybe you should take a look at some of the other utils. I worked on sort and ls and both have long been faster than their GNU equivalents.
> They don't seem to get enough experienced programmers fixing them up or usage for me to actually recommend anybody use them, but maybe that's changing.
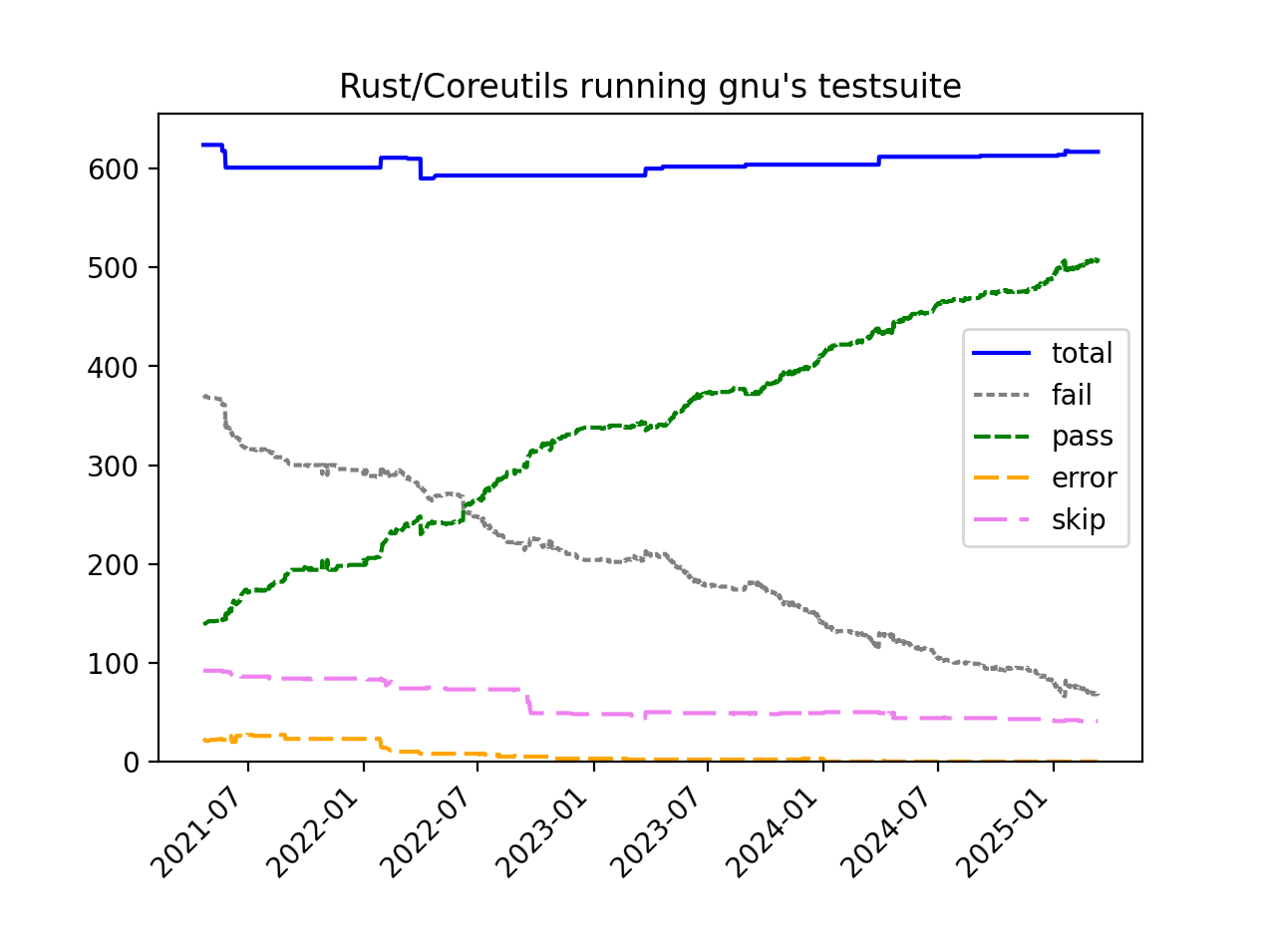
The issue is obviously compatibility and the uutils won't be broadly "usable" or stable until is hits 100% PASS/0% FAIL on the GNU test coverage, although the numbers are getting better and better. See: https://raw.githubusercontent.com/uutils/coreutils-tracking/...
> A lot of the Rust coreutils were written by people learning the language,
I really, really hate this way of framing the project -- which implicitly sounds like GNU is full of pros. Yes, lots of code was written by people just learning Rust and systems programming. Once it reaches parity on GNU test coverage, which it is rapidly approaching, GNU coreutils would wish it had this kind of enthusiasm behind it.
> and the code is often _more_ complicated than the corresponding code for the Unix utils.
I think it really depends. Much of the code is much simpler. For instance -- I think it's much easier to generically do hashing in Rust, and it shows.
I get what you're saying, but I don't care how it's called. Some things must die. Eg. Python 3 and the depreciation of was a very controversial step, but ultimately the right choice at the right time.
When all standards bodies and governments decide that POSIX is a hindrance which might take a few decades. And that is if they decide.
https://www.cisa.gov/sites/default/files/2023-12/The-Case-fo...
Python 3 is a hugely successful language and implementation, and almost no one regrets that it exists aside from a few noisy holdouts, and people who never liked any Python anywhere at any time.
That lead to a chicken and egg situation: if you depended on those libraries that did not migrate to python3 you where stuck at python 2 as well.
I believe being nice to the community and supporting python 2 for a long time was a mistake. They should have made a hard break and enforce the migration...
The Python ecosystem has been growing overall especially because of the success of things like Pandas, but a lot of backend/fullstack web app programming did move away from it and never looked back.
(Though you might say the more interesting question is: would they have moved away to things like Node for async/perf or JVM-stuff for "maintainability of old large codebase with lots of devs" issues? Maybe? But at this point Python has added in a lot of things from those languages; but maybe if they'd been there five years earlier with a cleaner upgrade story the migrations wouldn't have happened.)
But it's not even just that. Even within a major version it changes so much every few months and between different distros and platforms that random non-packaged scripts never work when moved from the authors fedora box to someone else's debian box, or god forbid bsd or sco or windows, or the same box a year later due to any number of random library/module differences.
It's great for the author and miserable for every other user.
It's ok for writing and using today and not at all for writing to keep.
It's ok for packaged apps where the package manager ensures that the script has exactly the environment it expects.
It's ok for controlled environments where the gods at the top have decreed that it is just part of the environment, so, large companies with IT departments and static published environments that everyone must use the same.
That's a lot of "it's ok"'s and so that's why it exists and is used in many places, but none of those changes why it's quite terrible.
I totally understand why developers love python, but as an end user I dread seeing the .py extension.
Where simplicity conflicted with compatibility, I've chosen the former so far. Targeting the BSD options and behavior is another example of that. The primary goal is to feel out the data flow for each utility, rather than dig into all the edges.
I wrote a blog post with the main AVX2 tricks [1] which includes how to deal with repeated white space when counting words
[1] https://stoppels.ch/2022/11/30/io-is-no-longer-the-bottlenec...
Most coreutil re-workings i’ve seen either double-down on JSON output, 24-bit color, sixels, & other lipsticks on the pig—without addressing any of the basic breakages we’ve become accustomed to—or they go off into an entirely different direction like nushell.
There is definitely room for improvement, but it is a thankless job.
https://www.cvedetails.com/product/5075/GNU-Coreutils.html?v...
{kind=link}