The answer to "why?" when DeepDream demoed hallucinated dog faces in 2015 was contemporary diffusion models.
Is it a world if there’s no permanence?
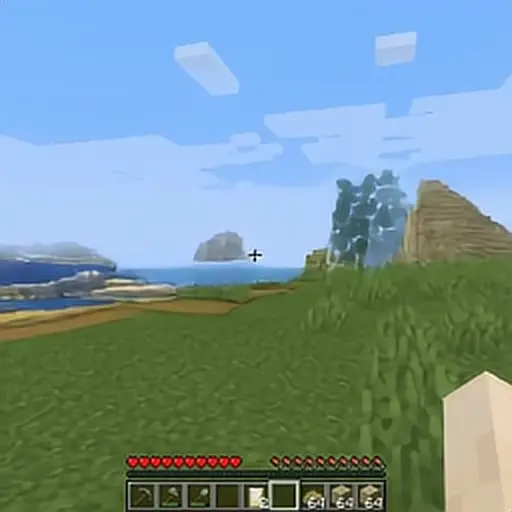
We’ve seen demos like this for a while now (granted not as fast) but the core problem is continuity. (Or some kind of object permanence)
It’s a problem for image generators as well.
I’d be more interesting if that was any closer to being solved than to have a real time Minecraft screenshot generator.
I may have missed it, but I didn’t see anything about prompting. I’d be surprised if this model could generalize beyond Minecraft at all.
It was, about a year ago. It's a solved problem.
Definitely nothing that maintains it for hours on end.
If you have, please link them. I’m very interested.
I don't want to be negative about someone else's project but I can completely understand why people are underwhelmed by this.
What I think will be the real application for AI in gaming isn't creating poorer versions of native code, it will be creating virtual novels that evolve with the player. Where characters are actual AI rather than following a predefined script. Where you, as the player, can change and shape the story as you wish. Think Star Trek Holodeck "holo-novels" or MMORPGs but can be played fully offline.
Rendering the pixels is possibly the worst application for AI at this stage because AI lacks reliable frame by frame continuity, rendering speed, nor an understanding of basic physics, which are all the bare minimum for any modern games engine.
"Why would you use this basic image diffusion model? It just creates a poorer version of existing images!" Is what your statement sounds like.
Obviously, you'd do the same thing with this game engine as is done with images. You combine together multiple world models, and thats almost the same as creating a new game.
Imagine playing minecraft and you could add a prompt "Now make complex rules for building space ships that can fly to different planets!" and it just mostly works, on the fly.
I’m not the OP and that’s not what my reply “sounds like”. You’re not reading my comment charitably.
> Obviously, you'd do the same thing with this game engine as is done with images. You combine together multiple world models, and thats almost the same as creating a new game.
That was actually my point.
Adding some VFX to a game engine doesn’t alter the game engines state.
What some of the proponents of this project are describing is akin to saying “ray tracing alters the game mechanics”.
It doesn’t matter how smart nor performant the AI gets at drawing pixels, it’s still just stateless pixels. This is why I was discussed practical applications of AI that can define the game engines state rather than just what you see on screen.
Image diffusion models specifically are not the right applications of AI to create and alter a persistent game state. And that’s why people are underwhelmed by this project.
It's probably not by just extending the context window or making the model larger, though that will of course help, because fundamentally external state and memory/simulation are two different things (right?).
Either way it seems natural that these models will soon be used for goal-oriented imagination of a task – e.g. imagine a computer agent that needs to find a particular image on a computer, it would continuously imagine the path between what it currently sees and its desired state, and unlike this model which takes user input, it would imagine that too. In some ways, to the best of my understanding, this already happens with some robot control networks, except without pixels.
- The inventory bar is mostly consistent throughout the play
- State transitions in response to key presses
- Block breakage over time is mostly consistent
- Toggling doors / hatches works as expected
- Jumping progresses with correct physics
Turning around and seeing approximately the same thing you saw a minute ago is probably just a matter of extending a context window, but it will inherently have limits when you get to the scale of an entire world even if we somehow can make context windows have excellent compression of redundant data (which would greatly help LLM transformers too). And I guess what I'm mostly wondering about is how would you synchronize this state with a ground truth so that it can be shared between different instances of the agent, or other non-agent entities.
And again, I think it's important to remember games are just great for training this type of technology, but it's probably more useful in non-game fields such as computer automation, robot control, etc.
My definition of state is something like reified bits of information, for which previous frames and such certainly count (knowing the current frame tells you a lot of information about the next frame vs not knowing the current frame).
The nice thing is that we can run tons of experiments at once. For Oasis v1, we ran over 1000 experiments (end-to-end training a 500M model) on the model arch, datamix, etc., before we created the final checkpoint that's deployed on the site. At Decart (we just came out of stealth yesterday: https://www.theinformation.com/articles/why-sequoias-shaun-m...) we have 2 teams: Decart Infrastructure and Decart Experiences. The first team provides insanely fast infra for training/inferencing (writes from scratch everything from CUDA to redoing the python garbage collector) -- we are able to get a 500M model to converge during training in ~20h instead of 1-2 weeks. Then, Decart Experiences uses this infra to create these new types of end-to-end "Generated Experiences"
My favorite example is: https://worldmodels.github.io/ (Not least of all because they actually simulate these simplified world models in your browser!)
Wait a few months, if someone is willing to use their 4090 to train the model, the technology is already here. If you could play a level of Doom than Mario should be even easier.
I ctrl-F'ed the webpage and saw 0 occurrence of "Minecraft". Why? This isn't a video game, this is a poor copy of a real video game you didn't even bother to say the name of, let alone credit it.
They can't say "Minecraft" because that's a Microsoft trademark, but they can use Minecraft images as training data, because everyone (including Microsoft) is using proprietary data to train diffusion models. There's the issue that the outputs obviously resemble Minecraft, but Microsoft has its own problems with Bing and DALL-E generating images that obviously resemble trademarked things (despite guardrails).
https://www.ign.com/articles/2013/05/16/nintendo-enforces-co...
> excellent, well-designed implementation
And there we see the problem laid bare. Excellent designs that are well-executed are not worthless facets of the real product. As we can see from Minecraft's success, that is the real product. People play video games for the experience, not to execute some logical construct a formal proof showing that it's fun. The reason that this demo uses Minecraft as opposed to a Minecraft knockoff is because Minecraft is better, and they are capitalizing on that. Even if that game is based on a well-worn concept, the many varied design problems you solve when making a game are harder than development, which is why damn near every game that starts open source is a knockoff of something other people already designed. It's not Mojang was some marketing powerhouse that knocked infiniminer off it's perch without merit.
Which is why I said "as a game, rather than the code", specifically. My whole point is that the elements which were assembled into it are not the valuable part!
I mean, what is Minecraft? Mine blocks, craft items. Fight skeletons, spiders, zombies and exploding zombies. The end boss is a dragon. It's Generic The Game.
The thing that the AI is training on is the thing without value - the look. Mojang gave that away in the billions of stream-hours, to their benefit.
Developers always think that these things have no value, yet as someone that's done a whole lot of work in both design and back-end development, the design and interface affect how people feel about the software far more than any technical underpinning. People play games because it makes them feel things, not because they want to interact with some novel game mechanic or use a technically superior engine.
And that is why pretty much the only open-source user-facing software with broad support— eg Firefox, blender, signal— are the ones that are foundation-backed with product managers that prioritize design. That's the core reason Mastodon failed to replace Twitter despite an incredible amount of momentum, the reason so few people use Linux desktops, and the reason that you'll have a hard time finding a professional photographer that's never tried gimp and an even harder time finding one that used it more than once. I've seen so many people pour thousands of collective hours into high-quality software with some cool conceptual ideas only for it to languish, unused. Developers know how much effort it takes to create software, and since they have a working mental model of how software works under the hood, they're far more tolerant to shitty interfaces. To most people, the interface IS the software. Developers, largely, have no clue what it takes to create high-quality design, and therefore undervalue it, and blame lack of FOSS adoption on commercial software marketing. User feedback doesn't support that assumption.
People buy things that look great just because they look great. When the pleasure of interaction is the whole point, technically or conceptually exceptional software with a substandard look and feel has no value.
When a scientific work uses some work and does not credit it, it is academic dishonesty.
Sure, they could have trained the model on a different dataset. No matter which source was used, it should be cited.
Why is this interesting? Today, not too interesting (Oasis v1 is just a POC). In the future (and by future I literally mean a few months away -- wait for future versions of Oasis coming out soon), imagine that every single pixel you see will be generated, including the pixels you see as you're reading this message. Why is that interesting? It's a new interface for communication between humans and machines. It's like why LLMs are interesting for chat, because they provide humans and machines an ability to interact in a way humans are used to (chat) -- here, computers will be able to see the world as we do and show back stuff to us in a way we are used to. TLDR: imagine telling your computer "create a pink elephant" and just seeing it popup in a game you're playing.
// ==UserScript==
// @name oasis.decart.ai
// @match https://oasis.decart.ai/*
// @run-at document-start
// ==/UserScript==
chrome = true;Very odd sensation indeed.
Would love to see some work like this but with world/games coming from a prompt.
What is this tech useful for? Genuine question from a long-time AI person.
At the end of the day, it should provide the same "API" as a game engine does: creators develop worlds, users interact with those worlds. The nice thing is that if AI can actually fill this role, then it would be: 1. Potentially much easier to create worlds/games (you could just "talk" to the AI -- "add a flying pink elephant here") 2. Users could interact with a world that could change to fit each game session -- this is truly infinite worlds
Last point: are we there yet? Ofc not! Oasis v1 is a first POC. Wait just a bit more for v2 ;)
I don't see how this does that, or is a step towards that. Help me see it?
Ostensibly, a game designer can then just "prompt" a new game concept they want to experiment with, and Oasis can dream it into a playable game.
For example, "an isometric top-down shooter, with Maniac mechanics, and Valheim graphics and worldcrafting, set in an ancient Nordic country"
And then the game studio will start building the actual game based on some final iteration of the concept prompt. A similar workflow already to concept art being "seeded" through Midjourney/SD/flux today.
1. Scale it up so that it has a longer context length than a single frame. If it could observe the last million frames, for example, that would allow significantly more temporal consistency.
2. RAG-style approaches. Generate a simple room-by-room level map (basically just empty bounding boxes), and allow the model to read the map as part of its input rather than simply looking at frames. And when your character is in a bounding box the model has generated before, give N frames of that generation as context for the current frame generation (perhaps specifically the frames with the same camera direction, even, or the closest to that camera direction). That would probably result in near-perfect temporal consistency even over very long generations and timeframes, assuming the frame context length was long enough.
3. Train on larger numbers of games, and text modalities, so that you can describe a desired game and get something similar to your description (instead of needing to train on a zillion Minecraft runs just to get... Minecraft.)
That being said I think in the near-term it'll be much more fruitful to generate game assets and put them in a traditional game engine — or generate assets, and have an LLM generate code to place them in an engine — rather than trying to end-to-end go from keyboard+mouse input to video frames without anything structured in between.
Eventually the end-to-end model will probably win unless scaling limits get hit, as per the Bitter Lesson [1], but that's a long eventually, and TBH at that scale there really may just be fundamental scaling issues compared to assets+code approaches.
It's still pretty cool though! And seems useful from a research perspective to show what can already be done at the current scale. And there's no guarantee the scaling limits will exist such that this will be impossible; betting against scaling LLMs during the gpt-2 era would've been a bad bet. Games in particular are very nice to train against, since you have easy access to near-infinite ground truth data, synthetically, since you can just run the game on a computer. I think you could also probably do some very clever things to get better-than-an-engine results by training on real-life video as well, with faked keyboard/mouse inputs, such that eventually you'd just be better both in terms of graphics and physics than a game engine could ever hope to be.
1: http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Easy. You do the same thing that we did with AI images, except with video game world models.
IE, you combine together multiple of them, and taking bits and pieces of each game "world model", but put together, is almost like creating an entirely new game.
> eventually without all the missing things like object permanence and other long-term state.
Well, just add in those other things with a much smaller set of variables. You are already sending in the whole previous frame, plus user input into the weights. I see no reason why you couldn't send in a simplified game state as well.
From the demo(that doesn't work on Firefox) you can see that it's overfit to the training set and it doesn't have a consistent state transition.
If you define it as a Markov decision process with states being images, actions being keyboard/mouse inputs, the probability transition being the transformer model, the model is a very poor one. Turning the mouse around shouldn't result in a completely different world, it should result in the exact same point of space from different camera orientation. You can fake it by fudging with the training data and augmenting with walking a bit, doing a 360 camera rotation and continuing the exploration but that will just overfit to that specific seed.
The page says their ASICs model inference supports 60+ players. Where are they shown playing together? What's the point of touting multiplayer performance when realistically, the poor state transition will mean those 60+ players are playing single player DeepDream Minecraft?
{kind=link}