Do they believe the guy marries a 30 years old cause she loves him?
In any case, who cares, how was that relevant..
> I told Larry this especially means a lot to me because my former #1 ranked Ph.D. student is now a professor in Michigan's Computer Science department with their famous Database Group.
The quotes from last year's bit on Ellison in sibling comment https://news.ycombinator.com/item?id=42567484 might help you make up your mind.
https://m.youtube.com/watch?t=33m1s&v=-zRN7XLCRhc&feature=yo...
> But the real big news in 2023 was how Elon Musk personally helped reset Larry's Twitter password after he invested $1b in Musk's takeover of the social media company. And with this $1b password reset, we were graced in October 2023 with Larry's second-ever tweet and his first new one in over a decade.
https://www.cs.cmu.edu/~pavlo/blog/2024/01/2023-databases-re...
> These journalists made it sound like Larry was doing something nefarious or indecent, like the time he made his pregnant third wife sign a prenup two hours before their wedding. I can assure you that Larry was only trying to use his vast wealth as the 7th richest person in the world to help his country. His participation in this call is admirable and should be lauded. Free and fair elections are not a trivial affair, like a boat race where sometimes shenanigans are okay as long as you win. Larry has done other great things with his money that are overlooked, like spending $370m on anti-aging research so that he can live forever
https://www.cs.cmu.edu/~pavlo/blog/2022/12/2022-databases-re...
The idea behind Redis data model is that "describe data" then "query those data in random ways" is conceptually nice but practically will not model very well many use cases. SQL databases plagued tech with performance issues for decades because of that. So Redis says instead: you need to put your data thinking about fundamental things like data structures and access times and the way you'll need those data back. And the API reflects this.
You don't have to automatically agree with that. But you have to understand that, then provide your "I'm against" arguments. Especially if you are in front of young people listening to you.
We have a database [1] and query language [2] that's tailored to storing & querying trace/telemetry data produced by different layers and components of cyber-physical systems for systems engineers to analyze, verify, and validate what a complex system is doing. It's not quite a traditional relational problem. It's not quite a traditional time series problem. It's not quite a traditional graph problem.
Addressing the way that systems engineers think about their domain in an effective way required coming up with something different. Are there caveats and rough edges? Sure. But, they're a lot less pernicious and onerous than the alternative of trying to leverage a bunch of ill-fitting menageries of different solutions.
Redis is fit-for-purpose. So, it makes sense that its query interface would also express that.
Sure...but all roads lead back to SQL eventually. Another recent example also mentioned in the OP is BigTable adopting SQL.
No it doesn't. SQL is designed for relational databases.
For other forms i.e. JSON, Graph, Key/Value they all use other query languages.
An extended Datalog[1] can provide performance optimizations not available to RDBMS.
It's not too hard to come up with alternatives that improve upon individual aspects of SQL like https://prql-lang.org/ but the barrier of entry is about as high as trying to make a huge social media network, most attempts will remain niche.
Then again, most software kind of sucks, it's just that some of it also works. For example, the Linux FHS reads like an overcomplicated structure that is the way it is for historical reasons, but works in practice.
Even in the various taxonomies of DBS in the research literature, Redis was mentioned with a wave of the hand as an "in-memory" database, which undersells the important (for me) part of the "data structure" server.
Putting the "database" after Redis could be a marketing misstep. Because it puts you in the is-it-sql territory.
TL;DR: Redis is mostly appreciated by practitioners (web) developers. Academics find it lacking a theoretical foundation, so... meh.
I don't think folks work with Redis out of fondness for the model, but because it's the least worst datastore for caching, lightweight message broker, and simple realtime things like counters.
Redis has probabilistic data structures, the ability to implement complex queueing patterns, and so forth. That's where the value is. Otherwise we would still be just with Memcached without caring about Redis. Another killer app was Twitter initial use case (then they used it for pretty much everything): to cache latest N Tweets, using capped lists. I could continue forever.
So OP argoment is flawed IMHO, for the above arguments, not fair. When you talk to students you need to make your homeworks. Really understand the system you are talking and provide a realistic image of it. Then, yes, if you want, criticize it as much as you want, with grounded arguments.
You know what? I re-read this comment and it's embarassing I ever have to write this, because after 15 years of Redis history at such scale and popularity, pretty much everybody that was seriously exposed to Redis knows those stuff. Is tech culture really degraded so much that we have to restate the obvious? Do I really need to explain GET/SET is not exactly where Redis shines after 15 years of half the Internet used all the kind of Redis patterns?
The API is just different compared to SQL, which is a downside for many. There's modern advancements in the space with IVM and more databases are supporting probabilistic data structures.
Maybe, though the author of the article is known to be a little bit too opinionated, and unfortunately habitual with phrasing himself in a bombastic manner. The piece reads like a dramatic recap of the past year's sporting events, littered with irrelevant and disconnected references to lyrics and drama in the world of rap and hip hop. A "quirky and fun" journalistic abortion.
My naive view is that you create a sorted set every time you define an index. that is, the opposite of "super hard to model with SQL"
I know you wrote OG and did a lot of Redis but...
Yes, Tech culture is that fucked.
In my past job I was hired semi-specifically to deal with a concern, namely that their use case 'fit well with Kafka' but the latency for their case sucked at least as much as the API pain. (Yes I did something better. No, IDK if folks will ever see it).
Now?
Now I spend my days trying to 'paper-over' patterns that drive me to insanity just trying to make it work from a 'people need to learn why things work on a starship' level [0].
On a real level you didn't fail, Redis has lots of great patterns. On a -practical- level it's a shitshow because you now have lots of folks 'glue-gunning' the Redis API on use cases that probably need tweaking or aren't the right fit at all, alas they all worked off the same example on GH/SO/etc and then did their own "this wasn't even the right way to do this so I'm adding glue, what could possibly go wrong" case.
(That said, Nats has decent stuff for this in form of KV CompareExchange style APIs, and I see the inspiration there, so that's something to feel good about.)
[0] - Namely, if anyone has a good prompt for taking a photo of someone and doing img2img of 'Person in astronaut uniform preaching from an ivory tower', that would be a plus
Is there a "to long didnt watch" summary any one knows of? I hate videos, but am curious lol
1. The Redis API requires the developer to use different commands to retrieve/manipulate data depending on the type of data being stored. To retrieve a string you use GET, but if you want to retrieve a list it's LRANGE, for a set it's SMEMBERS, for a hash it's HGETALL. (As opposed to an API design which would allow you to call GET on all of the different data types and have it return the right thing.)
2. The lack of a predefined schema means you can overwrite values with different types. So you can create a list named "foo" and then overwrite it with a string named "foo" and then overwrite that with a hash named "foo" and Redis will happily do it, meaning the developer needs to keep track on their end what actual type any given key is holding onto.
To me these criticisms come across as essentially saying "Redis doesn't behave like a RDBMS" to which I suppose antirez's point is "well, yeah, it's not supposed to".
In my example, the API on a key changes based on its value type. And the same collection can have different value types mixed together. You've recreated the worst parts of IBM IMS from the 1960s. However, the original version of IMS only changed the API when a collection's backing data structure changed. Redis can change it on every key!
We didn't get into the semantics of Redis' MULTI...EXEC, which the documentation mischaracterizes as "Transactions". I'm happy that at least you didn't use BEGIN...COMMIT.
I don't think you understood how Redis collections work. The items are just strings, they can't be mixed like integers or strings together or whatever, nor collections can be nested.
The Redis commands do type checking to ensure the application is performing the right operation.
In your example, GET against a list, does not make sense because:
1. GET is the retrieve-the-key-of-string-type operation.
2. Having GET doing something like LRANGE 0 -1 would have many side effects. Getting for error a huge list and returning a huge data set without any reason, creating latency issues. Also having options for GET to provide ranges (SQL alike query languages horror story). And so forth.
So each "verb" should do a specific action in a given data type. Are you absolutely sure you were exposed enough to the Redis API, how it works, and so forth?
About MULTI/EXEC, when AOF with fsync configured correctly is used, MULTI/EXEC provide some of the transactional guarantees you think when you hear "transaction", but in general the concept refers to the fact that commands inside MULTI/EXEC have an atomic effect from the point of view of an external observer AND point-in-time RDB files (and AOF as well). MULTI / INCR a / INCR a / EXEC will always result in the observer to see either 2, 4, 6, 8, and so forth, and never 3 or 5.
Anyway, I believe you didn't put enough efforts in understanding how really Redis works. Yet you criticized it with weak arguments in front of the most precious good we have: students. This is the sole reason why I wrote my first comment, I believe this to be a wrong teaching approach.
I think he makes the point that these "global variables" are dynamically typed; you can have "listX" and then write a non-list into that same name; statically typed systems would not allow this. He makes the fairly non-controversial point that a statically typed system (SQL, other than that of SQLite) adds a level of type safety that can guard against software bugs.
Well, that depends. In most SQL databases there are many cases where supplying the wrong type of value will implicitly convert to the expected type, often in unexpected ways that can result in subtle bugs.
as mentioned, SQLite breaks all these rules and I think SQLite is very wrong on this.
That's a tautological argument. The question isn't what the definition of GET is, but whether the design is good.
> 2. Having GET doing something like LRANGE 0 -1 would have many side effects. Getting for error a huge list and returning a huge data set without any reason, creating latency issues.
If this really were the reason, you'd have separate operations for tiny strings and huge strings. After all, by analogy having GET return a huge string "without any reason" would create latency issues.
But that's not how Redis works, right?
This does not meant that Redis would not work having generic LEN, INSERT, RANGE commands. But such commands would end also having type-specific options, that I have the feeling is not very clean. Anyway these are design tastes, but I don't think they dramatically change what Redis is or isn't. The interesting part is the data model, the idea of commands operating on abstract data structures, the memory-disk duality, and so forth. If one wants to analyze Redis, and understand merits and issues, a serious analysis should hardly focus on these kind of small choices.
Most sql databases (like Postgres) require all types to be declared once, and then they do type checking on mutation. In that sense, sql is like a static language like C. But weirdly, the results returned from a sql query are always dynamically typed values, expressed in a table. Applications reading data from sql will still typically need to know what kind of data they expect back - but they usually do that type checking at runtime.
Redis flips both of those choices. It’s dynamically typed - so it won’t check your mutations. But also, you don’t need schema migrations and all the complexity they bring. And rather than having a single “table” type, redis queries can return scalar values, lists or maps. What kind of return value you get back depends on the query function. (Eg GET vs LRANGE).
If you think of a database as the foundation underneath your house, static typing & type checking is a wonderful way to make that foundation more stable. There’s a reason Postgres is the default, after all. But redis isn’t best used like that. Instead, it’s a Swiss Army knife which is best used in small, specific situations in which a real database would be complex overkill. Stuff like caching, event processing, data processing, task queues, configuration, and on and on. Places where you want some of the advantages of a database (fast, concurrent network-accessible storage) but you don’t want to stress about tables and schema migrations.
If you really hate redis, maybe say the same thing I say about Java when I teach it to my students. “I hate this, and I’ll tell you why. But there are smart people out there who disagree with me.”
If you ask me, I wish sql looked more like redis in some ways. I think it’s quite awkward that every sql query returns exactly one “table”. I’d much rather if queries could return scalar values or even multiple tables, depending on your query.
Since when can't they?
Not everything is best described as a table, y’know?
Are they??? Not as I understand it.
select * from orders where custno = (select custno from customers where name = 'John Doe');
select * from orders where custno = 123456; -- John Doe's customer number
So I don't really see what the big problem is either way. Hoping I'm not being stupid AF, maybe you could explain further?
Imagine the programming language equivalent. We could make a programming language where every function call returns a table. If you expect 1 return value from your function, the caller grabs the first row out of the return array, and the first column out of that row. It would absolutely work, and that its mathematically equivalent in some sense. But it would be confusing, computationally inefficient and error prone. What happens if there's more than 1 row in the table? Or more than 1 column? What happens if the type of the columns doesn't match match what you expect? What happens if the table is empty? Or you want a function which returns a two lists instead of one? We could write that programming language. But it would be pretty weird and frustrating to use.
This is the situation today with SQL. Every query returns a dynamically typed table. Its up to the caller to parse that table.
With redis, the caller expresses to the database what kind of value they expect in the query function name. (At least, list or scalar). The database guarantees that a GET request always returns a scalar value, and LRANGE always returns a list. I think this has better ergonomics because the types are more explicit.
This is an interesting (and correct) perspective. Global variables scare us in software but we are ok with it when it comes to application state stored in a db.
The strongest argument against global variables is that they don’t show up in the parameter lists of functions. In that way, they’re sort of “spooky action at a distance”. And they encourage functions to be impure. But if this bothers you, you can always pass your database connection as an explicit parameter to any function which interacts with it.
This is yet another reason why single threaded should be the default assumption and multi-threaded require special consideration.
https://www.scattered-thoughts.net/writing/local-state-is-ha...
https://awelonblue.wordpress.com/2012/10/21/local-state-is-p...
Hmmm, this is a subtler issue than you make it out to be, I think, though I generally agree with you. The quality issues with Redis's technical design here interrelate substantially with user expectations/perceptions/squishier stuff.
The term "transaction" is anchored in most users' minds to a typical RDBMS transactional model assuming: a) some amount of state capture (e.g. snapshot) at the beginning of the transaction and b) "atomicity" of commit being interpreted as "all requested changes are atomically performed (or none are)" rather than "all requested changes are atomically attempted".
Redis has issues with both of those, so I'm sympathetic to your statement that what they call "transactions" is mis-characterized and would be better described as "best-effort command batching".
It's poor naming/branding to call it "transactions", and I don't think it had to be this way: MULTI/EXEC "transactions" should have been deprecated long ago--in favor of Redis scripts and other changes that should have been made in the Redis engine.
First, a defense of scripts: Redis scripts are, to a certain variety of user who wants transaction-esque functionality, not ideal. Those users may be reluctant to engage with a full procedural programming language rather than the database's query language. However, there's substantial overlap between those users and the ones who will be extremely confused by and unhappy with the existing MULTI/EXEC model--they're the folks with the most specific (wrong, in Redis) assumptions of how transactions should work, and suffer the most from them not working that way. Lua scripts, unfamiliar or not, are likely less troublesome in the long run for this cohort. Specifically, requiring users to be explicit about failure behavior of specific commands via call() vs. pcall() would remove one of the worst sharp edges of the MULTI/EXEC world.
Scripts can't answer other transaction-related needs, though. Ideally, I would have preferred that Redis go in the direction of a uniform set of conditions that can be applied to most write commands. There already are conditions in Redis, but they're not uniformly available: SET + NX/XX conditions single-key writes; WATCH semantically/implicitly conditions later EXEC commands with "if version of $key matches the version retrieved by the WATCH statement", etc. If that type of functionality were made explicit and uniformly available to all or most write operations, a further chunk of transaction-related needs could be addressed. When making single commands conditional isn't enough, scripts used to atomically batch-attempt commands could be invoked with parameters used to conditionalize those scripts' internal commands, and so on.
A final simple affordance in support of transaction-ish behavior would be a connection-scoped value type: either a modifier for arbitrary commands to have them operate on an empty database scoped to the connection, or a simple list-like value for connections to "stash" arbitrary data. This wouldn't fundamentally change any semantics, but would, at the cost of some indirection, marginally reduce the need for clients complexity when buffering conditions/commands for later flush via a pseudo-"commit"-script. This is somewhat hair-splitting, though: MULTI/EXEC is already such a connection-scoped buffer, just one that stages commands and not data. My hunch is that a data-only buffer to be consumed by scripts instead of "EXEC" would be an improvement here, but I may well be wrong.
Now, the system that results from these changes is still not as ergonomic/low friction as traditional transactions, and is especially unergonomic when users have to manually capture undo state and decide on rollback semantics during the failure of script execution. As Antirez mentioned in an adjacent comment, AOF can help ensure appropriate conistency in the face of database crashes during script execution, but database level reconciliation--aka "what is the equivalent of 'rollback' for a given script"--is still on the user to work out.
But that's what we're really talking about here, isn't it? That lack of undo (that is: the ability to capture and discard transactional state a la MVCC) is at the root of most of the weird and not-quite-transactional capabilities of Redis in this era.
Antirez is totally right that adding those capabilities would have substantially complicated the Redis engine, and I believe him when he says that made it not worth it to do so. Given that, I'd have vastly preferred a Redis which embraced providing tools that work in spite of/with full acknowledgement of that lack, rather than concealing it/confusing users by mis-branding MULTI/EXEC as "transactions".
Like offloading a shared data structure between threads / processes / machines so that I don’t have to deal with thread safety issues.
In Python you don't even need a lib, dict is thread safe even in nogil.
In Python you don't even need a lib, dict is thread safe even in nogil.
https://github.com/python/cpython/issues/112075
Google is recommending people not rely on it because it does make dict subclasses not substitutable. It's easy enough to avoid the issue completely so in most cases you might as well do that.
Especially if there’s a chance I’d want that data to persist across restarts.
It’s one thing if I’m using a BEAM language, but otherwise I’ll usually reach for Redis.
It's more a cultural thing than anything else. HN for example largely leans away from MS. It's quite interesting how little overlap there is between the two worlds sometimes.
Speaking as one of those people, it's just not my thing, so it's not on my radar at all. There's enough stuff happening outside MS to keep me busy forever.
How much is out of the box or simple easy to access configuration not magic incantations either you need expensive courses to know or be battle hardened with years of experience is the question really
See also scalability sections in these artcles:
https://airbyte.com/data-engineering-resources/oracle-vs-sql...
https://futuramo.com/blog/oracle-vs-sql-server-head-to-head-...
https://stackoverflow.blog/2008/09/21/what-was-stack-overflo...
It can work well performance-wise and security-wise, but programming it can be quite a pain, and I feel that’s unnecessarily so, considering what resources Microsoft has at their disposal.
I used this hack for backing up Oracle 30 years ago.
Something like 'mknod p backup.dmp; oradump .... file=backup; dd if=backup.dmp | ssh othermachine receiver-process'
Backups (at least db backups) used to be made with the assumption that the backup device is tape.
There is nothing to talk about here. It's boring database engine that powers boring business applications. It's pretty efficient and can scale vertically pretty well. With state of modern hardware, that vertical limit is high enough most people won't encounter it.
It's also going the way of Windows Server which is to say, it's being sold but not a ton of work is being done on it. Companies that are still invested in it are likely because they don't care about cost ultimately or cost of switching is too high to greenlight the switch.
Anyone who does care about cost like my current company has switched to OSS solutions like PostGres/MySQL/$RandomNoSQLOSSOption. My company switched away when turned into SaaS business and those MSSQL server costs ate into bottom line.
This has been happening throughout the ecosystem. Proget which is THE solution for .Net Artifacts is switching to PostGres: https://blog.inedo.com/inedo/so-long-sql-server-thanks-for-a...
Also, I saw this article from Brent Ozar, who I see as MSSQL smart person, which basically said if you have the option, just go with PostGres: https://www.brentozar.com/archive/2023/11/the-real-problem-w...
It's also worth noting that Microsoft even bought PostGres scaling solution called Citus so they read the writing on the wall: https://blogs.microsoft.com/blog/2019/01/24/microsoft-acquir...
I'm taking that as a positive thing... it's boring and does its job with little fanfare. That's pretty much what I want out of a RDBMS. So long as it is "fast-enough" with enough features for the applications that use it, that seems like a good place for an RDBMS to be.
One could still argue about Windows and licensing fees, but from a technical point of view, for business customers, boring isn't necessarily a bad thing.
It can also be a bit of a pain outside the C# ecosystem, whereas every language ever has nice postgres drivers that don’t require us to download arms setup ODBC. It runs on Linux as of a few years ago, but I also wouldn’t be surprised if many people didn’t realise that.
FWIW, it also powered the most popular (in terms of player base) MMORPG before WoW took over.
And I wouldn't be surprised to find it in aviation, railways, powerplants, grid control, etc...
I guess it was Lineage as Korean used mainly MSFT softwares?
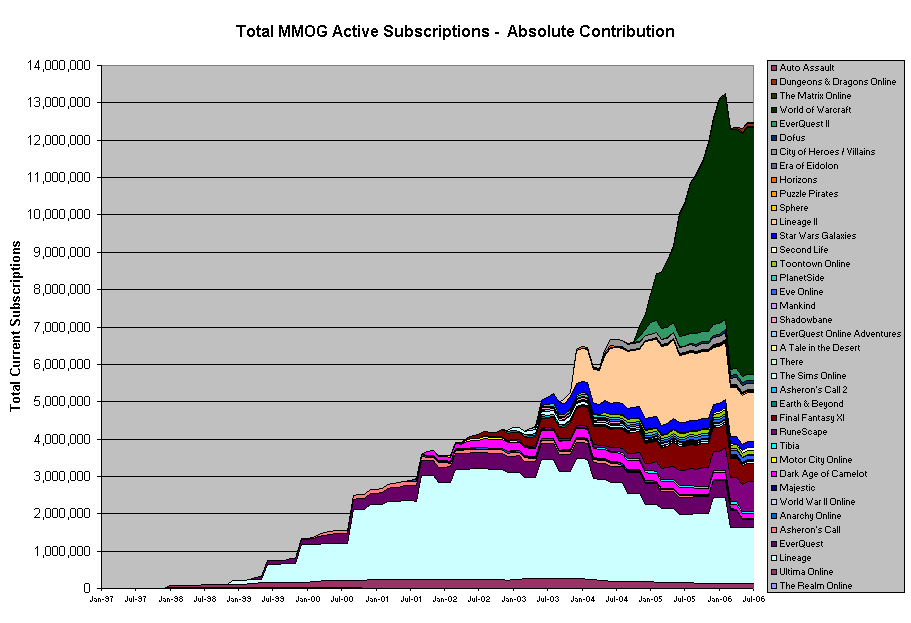
1. https://ics.uci.edu/~wscacchi/GameIndustry/MMOGChart-July200...
Some of these things are merely passable, some are great, but it's all included. The key takeaway is that SQL Server is a full data platform, not just an RDBMS.
- RDBMS: very solid, competitive in features - In-memory OLTP: (really a marketing name for a whole raft of algorithmic and architectural optimization) can support throughput that is an order of magnitude higher - OLAP: Columnstore index in RDBMS, can support pure DW style workload or OLAP on transactional data for near-real-time analytics - OLAP: SSAS: two different best-in-class OLAP engines: Multidimensional and Tabular for high-concurrency low-latency reporting/analytics query workloads - SSIS: passable only, but tightly integrated ETL tool; admittedly in maintenance mode - SSRS: dependable paginated / pixel-perfect reporting tool; similar to other offerings in this space - Native replication / HA / DR (one of the only things actually gated behind Enterprise) - Data virtualization: PolyBase
If you're just looking for a standard RDBMS, then there's little to justify the price tag for SQL Server. If you want to get value for money, you take advantage of the tight integration of many features.
There is value for having these things just work out of the box. How much value is up to you and your use cases.
Licensing isn't cheap. For anyone wondering, before discount, it's 876/yr per core for Standard and 3288/yr per core for Enterprise. Also note that Standard is limited to 24 cores and 128GB of RAM, if you want to unlock more of that, you must move to Enterprise.
I’d also note that most orgs and use cases probably don’t need more than 24 cores and 128GB RAM.
I think for an organization that wants a near-trivial out of the box experience with RDBMS, reporting, and analytics, Standard Edition is not a bad deal. Especially for the many organizations that are already using Microsoft as their identity provider and productivity suite.
Same thing is happening now to Postgres vs enterprisey DBs.
The profiling abilities of SQL Server Management Studio (SSMS) and its query execution insights, the overall performance and scalability, T-SQL support, in-memory OLTP, and temporal tables - I just love SQL Server.
I'm not sure if it's just that I learned SQL Server better in college than MySQL, Mongo or Postgres but it's just been an amazing UX dev experience throughout the years.
Granted, there's some sticky things in SQL Server, like backups/restores aren't as simple as I'd like, things like distributed transactions aren't straightforward, and obviously the additional licensing cost is a burden particularly for newer/smaller projects, but the juice is worth the squeeze IMHO.
Maybe algorithms review or TCS review or some specific math topic review next?
PSA: Hi kids, here's a dinosaur with yet more free advice: put the tiniest bit of effort into SQL early on and watch the compound interest add up.
Many developers will jump straight for ORMs when given the chance.
Oracle actually released 9.1 already in 2024. [1] And expect another release this month, and every quarter. So I think MySQL continues to get some new features bug fix and support like it used to. Contrary to most people think it is all going to Heatwave. I just hope Vector will be open source later as official to MySQL rather than behind Heatwaves.
[1] https://dev.mysql.com/doc/relnotes/mysql/9.1/en/news-9-1-0.h...
> OtterTune. Dana, Bohan, and I worked on this research project and startup for almost a decade. And now it is dead. I am disappointed at how a particular company treated us at the end, so they are forever banned from recruiting CMU-DB students. They know who they are and what they did.
Ouch.
> Lastly, I want to give a shout-out to ByteBase for their article Database Tools in 2024: A Year in Review. In previous years, they emailed me asking for permission to translate my end-of-year database articles into Chinese for their blog. This year, they could not wait for me to finish writing this one, so they jocked my flow and wrote their own off-brand article with the same title and premise.
Also sounds like he's preparing a new company:
> I hope to announce our next start-up soon (hint: it’s about databases).
For more context:
> I'm to sad to announce that @OtterTuneAI is officially dead. Our service is shutdown and we let everyone go today (1mo notice). I can't got into details of what happened but we got screwed over by a PE Postgres company on an acquisition offer. https://x.com/andy_pavlo/status/1801687420330770841
view-source:https://web.archive.org/web/20240827031455/https://ottertune...
scroll until you see ASCII art
Anyone care to explain how a company can screw another company via a acquisition offer?
DuckDB is a great tool. In April 2020, the creator of DuckDB gave a talk at CMU. In the beginning he makes a convincing argument (in 5 minutes) why data scientists don't use RDBMS and how this was the genesis of DuckDB. Here is a video that starts 3 minutes into the talk (where is argument starts): https://youtu.be/PFUZlNQIndo?si=ql9n2QuBlAEuGIqo&t=204
AFAIK people didn't take MongoDB seriously from the start, especially with the "web scale database" joke circulating. The Neo4j Community version has been under GPLv3 for quite some time, while the Enterprise version has always been somewhat closed, regardless of whether the source code was available on GitHub (the mentioned license change affected the Enterprise version).
Regarding CockroachDB, I must admit that I've only heard about it on HN and don't know anyone who seriously uses it. As for Kafka, there are two versions: Apache Kafka, the open-source version that almost everyone uses (under the Apache license), and Confluent Kafka, which is Apache Kafka enhanced with many additional features from Confluent, and the license change affected Confluent Kafka. In short, maybe the majority simply didn't care about these projects very much, so there is no major fork.
> It cannot be because the Redis and Elasticsearch install base is so much larger than these other systems, and therefore, there were more people upset by the change since the number of MongoDB and Kafka installations was equally as large when they switched their licenses.
I can’t speak for MongoDB, but the Confluent Kafka install base is significantly smaller than that of Apache Kafka, Redis and ES.
> Dana, Bohan, and I worked on this research project and startup for almost a decade. And now it is dead. I am disappointed at how a particular company treated us at the end, so they are forever banned from recruiting CMU-DB students. They know who they are and what they did.
Call me a skeptic, but I can't see this as a fair approach. If your company fails for whatever reasons, you should not recruit the university department/group/students against your peers (I can't find that CMU-DB was one of the founders of Ottertune).
Wrt Andy, here are [1] somehow interesting views from (presumably) previous employees.
[1] https://www.reddit.com/r/Database/comments/1dgaazw/comment/l...
But it is certainly not a popular choice there.
There are a lot of production uses.
Also, MongoDB charges an arm and a leg and does not make it particularly easy to self-host (and many newer features are limited to their hosting).
I am only seeing this now and I take the complaints about being "slightly racist and offensive" very seriously. I am checking with investors, former HR people, and co-founders. I was not made aware of any issues. If anything, I was overly cautious at the company.
I was openly transparent with our employees about every direction the company was pursuing up until the very end. The complaint that "He thinks he knows everything about business" makes me believe this person is just trolling because I was always the first to admit in meetings that I was not an expert in how to run a business. We had to fire people because of inappropriate behavior, but not because I had strong disagreements with how to run the company.
As a student who chose to stay at CMU for a PhD because of this group, it is quite the opposite situation - you may also misunderstand the nature of the "ban" (students can still apply directly to the company).
From the student perspective, we benefit from knowing the reputation of potential employers. For example: CompanyX went back on their promises so don't trust them unless they give it to you right away, CompanyY has a culture of being stingy, the people who went to CompanyZ love it there, and so on.
So it's more like (1) providing additional data about the company's past behavior, and (2) not actively giving the company a platform. I personally find this great for students.
> Postgres' support for extensions and plugins is impressive. One of the original design goals of Postgres from the 1980s was to be extensible. The intention was to easily support new access methods and new data types and operations on those data types (i.e., object-relational). Since 2006, Postgres' "hook" API. Our research shows that Postgres has the most expansive and diverse extension ecosystem compared to every other DBMS.
Greenhorn developers don't even know that there are non-Postgres databases which have extensions too - such is the gap! I wouldn't be surprised if Postgres had as many as all others combined.
Yes this can happen. But a lot of people don’t want a AWS managed service. They're like 30% cheaper for 30% less value. They can develop a bad reputation and feel like weird forks (kinesis vs Kafka) that have weird undocumented gotchas and edge cases that never get fixed. Many teams want to host on k8s anyway, and you’ll probably have better k8s support from the main project. Another example is the success of Flink over hosted Google Dataflow. Seems eventually the teams I know trend to the most mainstream OSS implementation over time, maybe after early prototyping on a managed system.
IMO it might not be the highest growth market anymore. Those who want to pay for a managed service will. But many are just figuring out a k8s based solution to their infra needs as k8s knowledge becomes more ubiquitous.
Umbra highlights: "Groupjoins enable efficient computation of aggregates, worst-case optimal joins handle complex queries on graph structured data, and range joins efficiently evaluate queries with conditions on location or time intervals." while Cedar includes in the hero: "CedarDB is a relational-first database system that delivers best-in-class performance for all your workloads, from transactional to analytical to graph,..."
The architecture is quite ancient at this point, but I'm not sure it's completely outdated. It's single-master shared-nothing, with shards distributed among replicas, similar to Citus. But the GPORCA query planner is probably the most advanced distributed query planner in the open source world at this point. From what I know, Greenplum/Cloudberry can be significantly faster than Citus thanks to the planner being smarter about splitting the work across shards.
Also, Greenplum 7 tracks postgres 14. Which is still old at this point, but not so bad as 12....
I also don't think I'd call the architecture ancient. Just very tightly coupled to postgres' own (as a fork of postgres that tries to ingest new versions from upstream every year or two) and paying the overhead of that choice in the modern landscape.
Source: former member of the Greenplum Kernel team.
Greenplum 7 is listed as tracking Postgres 12 in the release announcement [1], and the release notes for later 7.x versions don't mention anything. Is there a newer release with higher compatibility?
When I say ancient, I mean that it's a "classical" shared-nothing design where the database is partitioned and hosted as parallel, self-contained replica servers, where each node runs as a shard that could, in theory, by queried independently of the master database. This is in contrast to newer architectures where data is sharded at the heap level (e.g. Yugabyte, CockroachDB) and/or compute is separated from data (e.g. Aurora, ClickHouse, Neon, TiDB).
[1] https://greenplum.org/partition-in-greenplum-7-whats-new/
You're completely right, I had the wrong PG version in my memory. Embarrassing, thanks for catching that.
Here is the unofficial roadmap of Cloudberry:
1. Continuously upgrading the PostgreSQL core version, maintaining compatibility with Greenplum Database, and strengthening the product's stability. 2. End-to-end performance optimization to support near real-time analytics, including streaming ingestion, vectorized batch processing, JIT compilation, incremental materialized views, PAX storage format, etc. 3. Supporting lakehouse applications by fully integrating open data lake table formats represented by Apache Iceberg, Hudi, and Delta Lake. 4. Gradually transforming Cloudberry Database into a data foundation supporting AI/ML applications, based on Directory Table, pgvector, and PostgresML.
When original license is as restricted as AGPL it is unlikely there is much of embedded use... so less people are impacted in truly catastrophic way
Also if there is no contributor community to speak of... who is going to do the fork ?
I put some thoughts about it in my post about ScyllaDB https://peterzaitsev.com/thoughts-on-scylladb-license-change...
He mentions this in "Andy’s Take" section btw
Not sure what you mean by this? Virtual memory is implied by the CPU MMU and consequently OS kernel. Perhaps you meant they use a lot of custom memory allocation schemes?
Otherwise, I agree that the bar is quite high since (1) the problem at hand is already too complex (scalable LSM), and (2) pretty much anything in the code is custom made, e.g. avoiding the OS kernel as much as possible. And they pay peanuts for the skills needed to do the job.
jmalloc IME works really well.
It appears that a lot of attention is now directed at the folks doing 100 MB queries, and the high end has moved past everybody's radar. My idea of an exciting product is Ocient, who have skipped over Cloud and gone for hyperscale on-prem hardware. Yellowbrick is also a contender here.
I have a lot of experience with Vertica, and they seem to have gotten stuck in this niche as well, with sales tilted towards big accounts, but less traction in smaller shops, and a difficult road to get a SaaS or similar easy-start offering.
There's a crossover point where self-managed is cheaper than cloud, but nobody seems to have any idea where it is. Snowflake will gladly tell you that your sub-$1M Vertica cluster should be replaced by $10M of sluggish SaaS, and that you are saving money by doing so. These decisions seem more in the realm of psychology or political science.
DHH's cloud exit was a refreshing take on the expense issue, even if it wasn't strictly in the database space -- the cost per VCPU and so forth that he documented is a good start for estimating savings, and he debunked a lot of the "hidden costs" that cloud maximalists claim.
In the business/financial space the biggest news to me was the correction in Snowflake's stock price, which seemed to indicate that investors were finally noticing metrics like price-performance, but they added a little more AI and went back into irrationality.
I'm heavily in favor of DuckDB, Hudi, Iceberg, S3 tables, and the like. Mixing high-end and low-end tools seems like the best strategy (although settling on one high-end DWH has also worked IME), and the low end is getting better and cheaper, squeezing out the mid-range SaaS vendors.
In research I found Goetz Graefe's work in offset-value coding exciting -- he's wired it into query operators in a way that saves a lot of CPU on sorting and joins/aggregation. This is a technique that I've applied favorably in string sorting, and it was discovered in the DB community decades ago but largely forgotten. (This work precedes 2024, but I'm a slow study.)
Single data point here: before cloud managed dbs were a thing our smallish startup was running mysql on virtual servers by installing it from the linux package manager. Always worked great, runs without needing manual attention for years at a time once set up, so I've never felt the need to change.
So at least in some cases the crossover point is "right from the start".
Silicon Valley doesn't have a good record in the DB/DWH space; producing a fully-featured DBMS doesn't seem to fit the VC model.
Redis while not having some of the features he mentions in [1] (i.e. SQL), when used for what it excels at is usually not considered "slow".
As an in-memory data structure server, a common use case is to use it for where some operations in a typical RDBMS are slow.
1. It is single-threaded, which severely limits throughput for a single instance.
2. All communication must go over a socket, which severely impacts latency for use cases where it could otherwise run in-process.
[0] https://www.microsoft.com/en-us/research/blog/introducing-ga...
[1] https://news.ycombinator.com/item?id=39752504
[2] https://microsoft.github.io/garnet/docs/commands/api-compati...
If anything this shows how insanely difficult it must be to succeed as a database startup (when was the most recent startup success in this space?), as the founding team is stellar.
On the other hand I am surprised it died this quick and interested to know if they did a proper postmortem. Not only did they raise way more than is needed to survive for three years but the idea is about utilising AI to improve DB performance and I find it hard to imagine they couldn't find more investors to lend them a lifeline with all the AI hype.
- most people don't need it
- People who do need it having DBAs/Operations people
- or consultancies
- Database vendors that have automatic optimisation as a feature
Ok "AI" in the name but I think for something as specific as DB optimisation AI jazz hands probably don't work as well. Writing it out it almost seems harder than being an actual DB vendor.
[0] https://techcrunch.com/2024/03/12/new-startup-from-postgres-...
Of course it’s not to be used as a general purpose DB it’s keys and values. Used for caches and things like that. In my experience in real world scenarios and loads vanilla single threaded Redis is stable, fast, and nigh bulletproof.
I don’t care about the billion-dollar drama behind a piece of tech, but Redis defined the key-value query API for many similar databases. Trashing it just because it isn’t SQL-like feels unjustified.
A little sad Andy didn't share more of his thoughts on the intersection between Data and AI, and how that's going to evolve.
One factual issue: "The university had previously announced that this player was transferring from Louisiana State to Michigan." This is not true. Underwood had committed to LSU but then switched his commitment to Michigan. He was still in high school at the time, and has never attended LSU.
But, do you really expect a funny database prof to know much about football?
I have! It's a pretty good no-code/minimal-code graphical ELT+Analytics in one tool. It's one of those alternate-universe tools that has it's own way of doing things from everything else in the industry, but it’s pragmatic and the people who use it tend to love it.
The one thing that makes it viable is that is has/had (pre-acquisition) very aggressive compatibility with anything else that can hold data, so you can use it as a bolt-on to whatever other databases or files your company has.
Despite what the PE press release about the acquisition says, it has virtually nothing to do with AI, at lease in the modern big NN sense.
If you're looking to fix your giant pile of alteryx workbooks or migrate them to something else, hmu
I worked at a company for a while that used QLDB as the primary system of record. The idea is great but the problem is that due to performance and other QLDB limitations all data had to be mirrored to an RDBMS via a streaming/queuing system, and there always were programmatic errors in interpreting data arriving for import into the RDBMS ... text field too long for RDBMS field; wrong data type or overflowing integer; invalid text encoding; ... Etc. These errors had to be noticed, debugged, fixed, and data had to be re-streamed. In the meantime official transactions were missing from the RDBMS side, which was used for reporting, driving the UI, deriving monetary obligations, etc. it was not worth the trouble. (I was lucky to not be involved in that design or implementation.)
The link for "MariaDB corporation" points to an empty image with white colour background. Can anyone explain the context here?
for a moment i got reminded of the rap music in your courses
im glad that tigerbeetle got here, really impressive team they have.
there are a lot of other missing alien technologies i've discovered recently too like quickwit which is like elasticsearch but s3-compatible, and typesense which is like elasticsearch but memory-based
guys, what are we doing here. this is ridiculous. andy pavlo cannot get an article on wikipedia? have you seen his work?
{kind=link}