Presumably the pro hardware based on the same silicon will have 64GB, they usually double whatever the gaming cards have.
I like business cards, I'm going to stick with that one. Dibs.
It even has a low mantissa FMA.
https://www.youtube.com/watch?v=zBAxiQi2nPc
I assume someone is doing rendering on them given the OpenGL support. In theory, you could do rendering in CUDA, although it would be missing access to some of the hardware that those who work with graphics APIs claim is needed for performance purposes.
While they've come a long way, I'd imagine they're still highly specialized compared to general-purpose hardware and maybe still graphics-oriented in many ways. One could test this by comparing them to SGI-style NUMA machines, Tilera's tile-based systems, or Adapteva's 1024-core design. Maybe Ambric given it aimed for generality but Am2045's were DSP-style. They might still be GPU's if they still looked more like GPU's side by side with such architectures.
A tensor operation is a generalization of a matrix operation to include higher order dimensions. Tensors as used in transformers do not use any of those higher order dimensions. They are just simple matrix operations (either GEMV or GEMM, although GEMV can be done by GEMM). Similarly, vectors are matrices, which are tensors. We can take this a step further by saying scalars are vectors, which are matrices, which are tensors. A scalar is just a length 1 vector, which is a 1x1 matrix, which is a tensor with all dimensions set to 1.
As for the “tensor” instructions, they compute tiles for GEMM if I recall my read of them correctly. They are just doing matrix multiplications, which GPUs have done for decades. The main differences are that you do not need need to write code to process the GEMM tile anymore as doing that is a higher level operation and this applies only to certain types introduced for AI while the hardware designers expect code using FP32 or FP64 to process the GEMM tile the old way.
Press the power button, boot the GPU?
Surely a terrible idea, and I know system-on-a-chip makes this more confusing/complicated (like Apple Silicon, etc.)
CPUs are not fast or slow. GPUs are not fast or slow. They are fast and slow for certain workloads. Contra popular belief, CPUs are actually really good at what they do, and the workloads they are fast at are more common than the workloads that GPUs are fast at. There's a lot to be said for being able to bring a lot of power to bear on a single point, and being able to switch that single point reasonably quickly (but not instantaneously). There's also a lot to be said for having a very broad capacity to run the same code on lots of things at once, but it definitely imposes a significant restriction on the shape of the problem that works for.
I'd say that broadly speaking, CPUs can make better GPUs than GPUs can make CPUs. But fortunately, we don't need to choose.
Any modern card under $1000 is more than enough for graphics in virtually all games. The gaming crisis is not in a graphics card market at all.
I barely play video games but I definitely do
I still play traditional roguelikes from the 80s (and their modern counterparts) and I'm a passionate gamer. I don't need a fancy GPU to enjoy the masterpieces. Because at the end of the day nowhere in the definition of "game" is there a requirement for realistic graphics -- and what passes off as realistic changes from decade to decade anyway. A game is about gameplay, and you can have great gameplay with barely any graphics at all.
I'd leave raytracing to those who like messing with GLSL on shadertoy; now people like me have 0 options if they want a good budget card that just has good raster performance and no AI/RTX bullshit.
And ON TOP OF THAT, every game engine has turned to utter shit in the last 5-10 years. Awful performance, awful graphics, forced sub-100% resolution... And in order to get anything that doesn't look like shit and runs at a passable framerate, you need to enable DLSS. Great
Really, these are the only 2 situations where ray tracing makes much of a difference. We already have simulated shadowing in many games and it works pretty well, actually.
Silent Hill 2 Remake and Black Myth: Wukong both have a meaningful amount of water in them and are improved visually with raytracing for those exact reasons.
https://www.youtube.com/watch?v=iyn2NeA6hI0
Can you please point at the mentioned effects here? Immersion in what? Looks like PS4-gen Tomb Raider to me, honestly. All these water reflections existed long before RTX, it didn't introduce reflective surfaces. What it did introduce is dynamic reflections/ambience, which are a very specific thing to be found in the videos above.
does improve immersion and feels nice to look at
I bet that this is purely synthetic because RTX gets pushed down the players throat by not implementing any RTX-off graphics at all.
Just taking this one, you actually make a point about having a raytracing-ready graphics card for me. If all the games are doing the hard and mathematically taxing reflection and light-bouncing work through raytracing now and without even an option for non-raytraced, then raytracing is where we're going and having a good RT card is, now or very soon, a requirement.
Why are you so hostile? I'm not justifying the cost, I'm simply in the 4k market and replying to OP's statement "Any modern card under $1000 is more than enough for graphics in virtually all games" which is objectively false if you're a 4k user.
I disagree. I run a 4070 Super, Ryzen 7700 with DDR5 and I still cant run Asseto Corsa Competizione in VR at 90fps. MSFS 2024 runs at 30 something fps at medium settings. VR gaming is a different beast
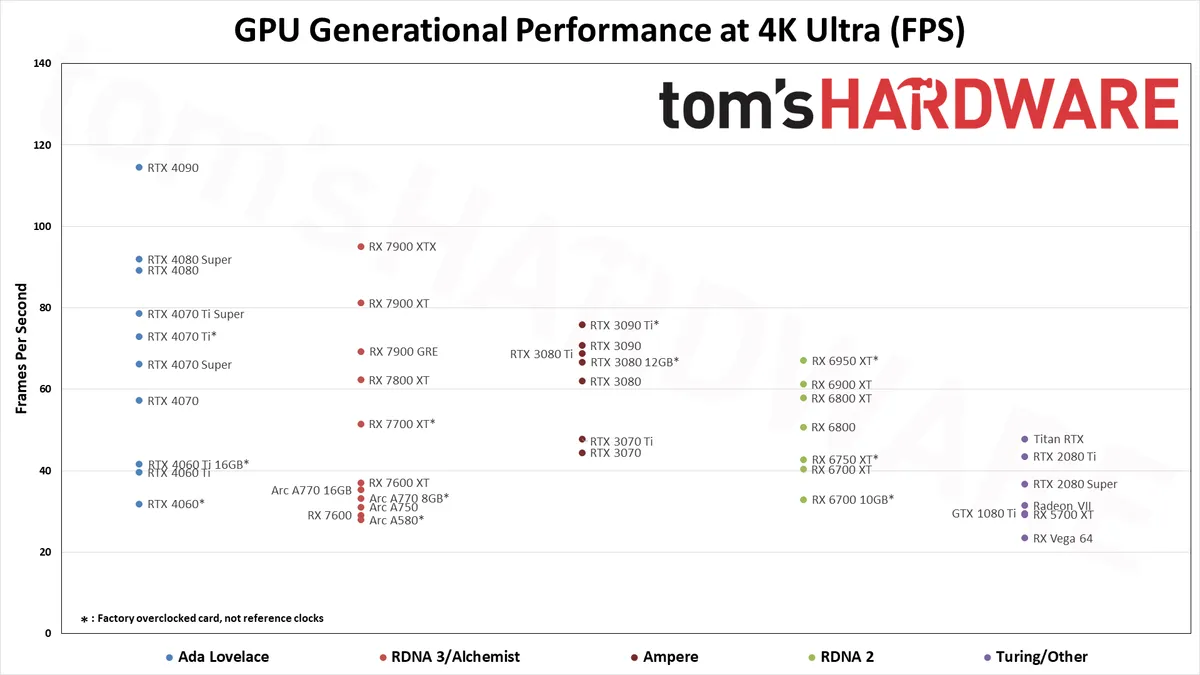
Now, I do agree that $1000 is plenty for 95% of gamers, but for those who want the best, Nvidia is pretty clearly holding out intentionally. The gap between a 4080TI and a 4090 is GIANT. Check this great comparison from Tom's Hardware: https://cdn.mos.cms.futurecdn.net/BAGV2GBMHHE4gkb7ZzTxwK-120...
The biggest next-up offering leap on the chart is 4090.
* also you want to ensure your CPU doesn't C1E-power-cycle every frame and your frametimes don't look like EKG. There's much more to performance tuning than just buying a $$$$$ card. It's like installing a V12 engine into a rusted fiat. If you want performance, you want RTSS, AB, driver settings, bios settings, then 4090.
I went from 80 FPS (highest settings) to 365 FPS (capped to my alienware 360hz monitor) when I upgraded from my old rig (i7-8700K and 1070GTX) to a new one ( 7800X3D and 3090 RTX)
Btw, if you're using gsync or freesync, don't allow your display to cap it, keep it 2-3 frames under max refresh rate. Reddit to the rescue.
You will love the RTX 5080 then. It is priced at $999.
Me. I do. I *love* raytracing; and, as has been said and seen for several of the newest AAA games, raytracing is no longer optional for the newest games. It's required, now. Those 1080s, wonderful as long as they have been (and they have been truly great cards) are definitely in need of an upgrade now.
Does anyone know what these might cost in the US after the rumored tariffs?
I have to admit with the display wrapping around into peripheral vision, it is very immersive.
People read too much into "designed for RDNA4".
Why would they write that on their marketing slides?
I can tell the difference in games if I go looking for it, but in the middle of a tense shootout I honestly don't notice that I have double the DPI.
[1] https://www.youtube.com/watch?v=iQ404RCyqhk
[2] https://rog.asus.com/monitors/27-to-31-5-inches/rog-swift-ol...
If DLSS4 and “MOAR POWAH” are the only things on offer versus my 3090, it’s a hard pass. I need efficiency, not a bigger TDP.
Turn down a few showcase features and games still look great and run well with none or light DLSS. UE5 Lumen/ray tracing are the only things I feel limited on and until consoles can run them they'll be optional.
It seems all the gains are brute forcing these features with upscaling & frame generation which I'm not a fan of anyway.
Maybe a 7090 at this rate for me.
https://wccftech.com/nvidia-is-rumored-to-switch-towards-sam...
Coincidentally, the 3090 was made using Samsung's 8nm process. You would be going from one Samsung fabricated GPU to another.
I suspect there is a correlation to the price that it costs Nvidia to produce these. In particular, the price is likely 3 times higher than the production and distribution costs. The computer industry has always had significant margins on processors.
If the only way to get better raw frames in modern GPUs is to basically keep shoveling power into them like an old Pentium 4, then that’s not exactly an enticing or profitable space to be in. Best leave that to nVidia and focus your efforts on a competitive segment where cost and efficiency are more important.
As always wait for fairer 3rd party reviews that will compare new gen cards to old gen with the same settings.
Not necessarily. Look at the reprojection trick that lots of VR uses to double framerates with the express purpose of decreasing latency between user movements and updated perspective. Caveat: this only works for movements and wouldn't work for actions.
They may resurrect it at some stage, but at this stage yes.
By the way, this is even better as far as memory size is concerned:
https://www.asrockrack.com/minisite/AmpereAltraFamily/
However, memory bandwidth is what matters for token generation. The memory bandwidth of this is only 204.8GB/sec if I understand correctly. Apple's top level hardware reportedly does 800GB/sec.
As for how well those CPUs do with LLMs. The token generation will be close to model size / memory bandwidth. At least, that is what I have learned from local experiments:
https://github.com/ryao/llama3.c
Note that prompt processing is the phase where the LLM is reading the conversation history and token generation is the phase where the LLM is writing a response.
By the way, you can get an ampere altra motherboard + CPU for $1,434.99:
https://www.newegg.com/asrock-rack-altrad8ud-1l2t-q64-22-amp...
I would be shocked if you can get any EYPC CPU with similar/better memory bandwidth for anything close to that price. As for Strix Halo, anyone doing local inference would love it if it is priced like a gaming part. 4 of them could run llama 3.1 405B on paper. I look forward to seeing its pricing.
As for price the AMD Epyc Turin 9115 is $726 and a common supermicro motherboard is $750. Both the Ampere and AMD motherboards have 2x10G. No idea if the AMD's 16 cores with Zen 5 will be able to saturate the memory bus compared to 64 cores of the Amphere Altra.
I do hope the AMD Strix Halo is reasonably priced (256 bits wide @ 8533 MHz), but if not the Nvidia Digit (GB10) looks promising. 128GB ram, likely a wider memory system, and 1 Pflop of FP4 sparse. It's going to be $3k, but with 128GB ram that is approaching reasonable. Seems like it's likely has around 500GB/sec of memory bandwidth, but that is speculation.
Interesting Ampere board, thanks for the link.
That's not even close, the M4 Max 12C has less than a third of the 5090s memory throughput and the 10C version has less than a quarter. The M4 Ultra should trade blows with the 4090 but it'll still fall well short of the 5090.
I’m expecting a minor bump that will look less impressive if you compare it to watts, these things are hungry.
It’s hard to get excited when most of the gains will be limited to a few new showcase AAA releases and maybe an update to a couple of your favourites if your lucky.
On pc you can turn down the fancy settings at least but For consoles I wonder if we’re now in the smudgy upscale era like overdone bloom or everything being brown.
EDIT: The _other_ huge issue with Nanite is overdraw with thin/aggregate geo that 2pass occlusion culling fails to handle well. That's why trees and such perform poorly in Nanite (compared to how good Nanite is for solid opaque geo). There's exciting recent research in this area though! https://mangosister.github.io/scene_agn_site.
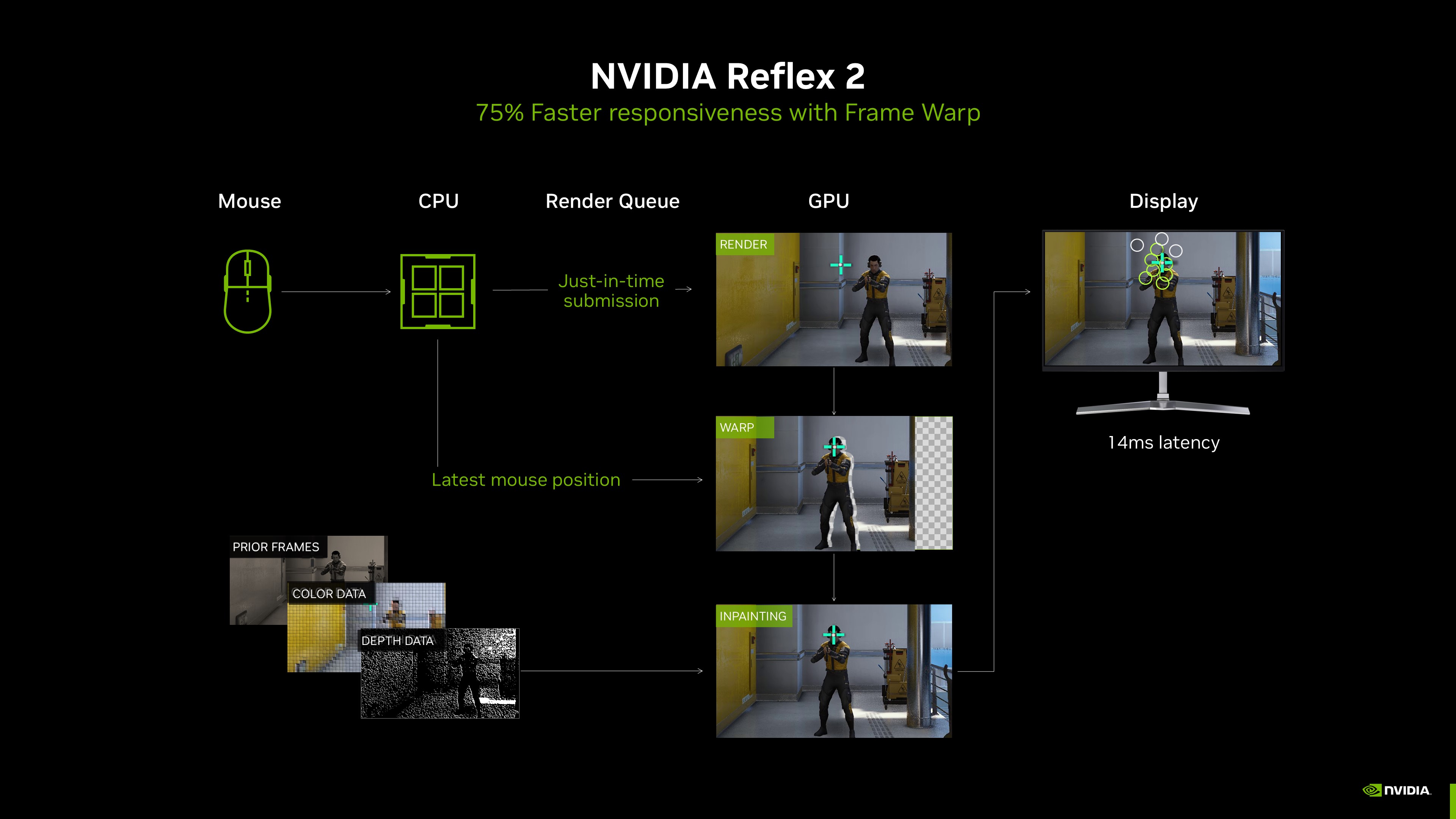
There’s also the new reflex 2 which uses reprojection based on mouse motion to generate frames that should also help, but likely has the same drawback.
Do you have a source for this? Doesn't sound like a very good idea. Nor do I think there's additional latency mind you, but not because it's not interpolation.
It is also just plain unsound to think that it'd not be interpolation - extrapolating frames into the future means inevitably that future not coming to be, and there being serious artifacts every couple frames. This is just nonsense.
I checked through (the autogenerated subtitles of) the entire keynote as well, zero mentions there either. I did catch Linus from Linus Tech Tips saying "extrapolation" in his coverage [1], but that was clearly meant colloquially. Maybe that's where OP was coming from?
I will give you that they seem to intentionally avoid the word interpolation, and it is reasonable to think then that they'd avoid the word extrapolation too. But then, that's why I asked the person above. If they can point out where on that page I should look for a paragraph that supports what they were saying, not with a literal mention of the word but otherwise, it would be good to know.
[0] https://www.nvidia.com/en-us/geforce/news/dlss3-ai-powered-n...
Extrapolation means you have frame 1, and sometime in the future you'll get a frame 2. But until then, take the training data and the current frame and "guess" what the next few frames will be.
Interpolation requires you to have the final state between the added frames, extrapolation means you don't yet know what the final state will be but you'll keep drawing until you get there.
You shouldn't get additional latency from generating, assuming it's not slowing down the traditional render generation pipeline.
it's certainly not reduced lag relative to native rendering. It might be reduced relative to dlss3 frame gen though.
To me this sounds not quite right, because while yes, you'll technically be more frames behind, those frames are also presented for a that much shorter period. There's no further detail available on this it seems however, so people have pivoted to the human equivalent of LLM hallucinations (non-sequiturs and making shit up then not being able to support it, but also being 100% convinced they are able to and are doing so).
Digital Foundry has actual measurements, so whether or not that matches your intuition is irrelevant. But I think the part you forgot is that generating the frames still takes time in and of itself, and you then need to still present those at a consistent rate for motion smoothness.
> Digital Foundry has actual measurements, so whether or not that matches your intuition is irrelevant.
I mean, it's pretty relevant to me. Will watch it later then.
The Digital Foundry initial impressions are promising, but for me with a 144hz monitor that prefers V-Sync with an an FPS cap slightly below, I'm not sure using 3x or 4x mode will be desirable with such a setup, since that would seemingly make your input lag comparable to 30fps. It seems like these modes are best used when you have extremely high refresh rate monitors (pushing 240hz+).
I'm guessing users will self tune to use 2x/3x/4x based on their v-sync preference then.
So Nvidia's example of taking cyberpunk from 28fps to 200+ or whatever doesn't actually work. It'll still feel like 20fps sluggish watery responses even though it'll look smooth
likely 10-30% going off of both the cuda core specs (nearly unchanged gen/gen for everything but the 5090) as well as the 2 benchmarks Nvidia published that didn't use dlss4 multi frame gen - Far Cry 6 & A Plague Tale
https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
Only way to fix this is for AMD to decide it likes money. I'm not holding my breath.
It's not dissimilar to what happened to Boeing. I'm a capitalist, but the current accounting laws (in particular corporate taxation rules) mean that all companies are pushed to use money for stock buybacks than R&D (which Intel spent more on the former over the latter over the past decade and I'm watching Apple stagnate before my eyes).
Next generation, the are finally reversing course and unifying their AI and GPU architectures (just like nVidia).
2026 is the big year for AMD.
Meanwhile their CPU marketing has numbers and graphs because their at the top of their game and have nothing to hide.
I'm glad they exist because we need the competition, but the GPU market continues to look dreary. At least we have a low/mid range battle going on between the three companies to look forward to for people with sensible gaming budgets.
However, I’m a AAA gamedev CTO and they might have been telling me what the card means to me.
https://www.nvidia.com/en-us/geforce/technologies/8k/
That said, I recall that the media was more enthusiastic about christening the 4090 as an 8K card than Nvidia was:
https://wccftech.com/rtx-4090-is-the-first-true-8k-gaming-gp...
https://www.nvidia.com/en-us/geforce/news/geforce-rtx-3090-8...
It's uncommon, sure, but as mentioned it was sold to me as being a development board for future resolutions.
On the planet? Many people. Maybe you're thinking 12K or 16K.
The value just wasn't there and probably won't ever be for most use cases. XR equipment might be an exception, video editing another.
Someone else probably said that years ago when everyone was rocking 1080/1440p screens.
How many of the cards of that time would you call “4K cards”? Even the Titan X that came a couple of years later doesn’t really cut it.
There’s such a thing as being too early to the game.
What gamers look for is more framerate not particularly resolution. Most new gaming monitors are focusing on high refresh rates.
8K feels like a waste of compute for a very diminished return compared to 4K. I think 8K only makes sense when dealing with huge displays, I’m talking beyond 83 inches, we are still far from that.
Which would then imply that you don't need a display as big as 83" to see the benefits from 8K. Still, we're talking about very large panels here, of the kind that wouldn't even fit many computer desks, so yeah...
P.S. Also, VR. For VR you need 2x4k at 90+ stable fps. There's (almost) no vr games though
What "modern games" and "modern cards" are you specifically talking about here? There are plenty of AAA games released last years that you can do 4K at 60fps with a RTX 3090 for example.
I’d say the comparison is what’s faulty, not the example.
I’ve done tons of custom stuff but was at a point where I didn’t have the time for a custom loop. Just wanted plug and play.
Seen some people talking down the block, but honestly I run 50c under saturated load at 400 watts, +225 core, +600 memory with a hot spot of 60c and VRAM of 62c. Not amazing but it’s not holding the card back. That’s with the Phanteks T30’s at about 1200RPM.
Stock cooler I could never get the card stable despite new pads and paste. I was running 280 watts, barely able to run -50 on the core and no offset on memory. That would STILL hit 85c core, 95c hotspot and memory.
Not when you turn on ray tracing.
Also 60fps is pretty low, certainly isn't "high fps" anyway
You can't get high frame rates with path tracing and 4K. It just doesn't happen. You need to enable DLSS and frame gen to get 100fps with more complete ray and path tracing implementations.
People might be getting upset because the 4090 is WAY more power than games need, but there are games that try and make use of that power and are actually limited by the 4090.
Case in point Cyberpunk and Indiana Jones with path tracing don't get anywhere near 100FPS with native resolution.
Now many might say that's just a ridiculous ask, but that's what GP was talking about here. There's no way you'd get more than 10-15fps (if that) with path tracing at 8K.
Cyberpunk native 4k + path tracing gets sub-20fps on a 4090 for anyone unfamiliar with how demanding this is. Nvidia's own 5090 announcement video showcased this as getting a whopping... 28 fps: https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2Ff...
I’m sure some will disagree with this but most PC gamers I talk to want to be at 90FPS minimum. I’d assume if you’re spending $1600+ on a GPU you’re pretty particular about your experience.
I don’t really mind low frame rates, but latency is often noticeable and annoying. I often wonder if high frame rates are papering over some latency problems in modern engines. Buffering frames or something like that.
Uhhhhhmmmmmm....what are you smoking?
Almost no one is playing competitive shooters and such at 4k. For those games you play at 1080p and turn off lots of eye candy so you can get super high frame rates because that does actually give you an edge.
People playing at 4k are doing immersive story driven games and consistent 60fps is perfectly fine for that, you don't really get a huge benefit going higher.
People that want to split the difference are going 1440p.
For me, I'd rather play a story based shooter at 1440p @ 144Hz than 4k @ 60Hz.
Also nobody is buying a 4090/5090 for a "fine" experience. Yes 60fps is fine. But better than that is expected/desired at this price point.
I think the textures and geometry would have the same resolution (or is that not the case? but in 4K if you walk closer to the wall you'd want higher texture resolution as well anyway, if the graphics artists have made the assets at that resolution anyway)
8K screen resolution requires 132 megabytes of memory to store the pixels (for 32-bit color), that doesn't explain gigabytes of extra VRAM
I'd be curious to know what information I'm missing
I didn't know of anyone who used the Titan cards (which were actually priced cheaper than their respective xx90 cards at release) for gaming, but somehow people were happy spending >$2000 when the 3090 came out.
Of course they did, the 3090 came out at the height of the pandemic and crypto boom in 2020, when people were locked indoors with plenty of free time and money to spare, what else where they gonna spend it on?
It probably serves to make the 4070 look reasonably priced, even though it isn't.
https://www.techpowerup.com/gpu-specs/geforce-rtx-5070.c4218
https://www.techpowerup.com/gpu-specs/geforce-rtx-5090.c4216
It is unlikely that the 5070 and 5090 share the same die when the 4090 and 4080 did not share same die.
Also, could an electrical engineer estimate how much this costs to manufacture:
https://videocardz.com/newz/nvidia-geforce-rtx-5090-pcb-leak...
It’s not. 14L PCB are expensive. When I looked at Apple cost for their PCB it was probably closer to $50, and they have smaller area
4090 was already priced for high income (in first world countries) people. Nvidia saw 4090s were being sold on second hand market way beyond 2k. They merely milking the cow.
https://www.okdo.com/wp-content/uploads/2023/03/jetson-agx-o...
The 3090 Ti had about 5 times the memory bandwidth and 5 times the compute capability. If that ratio holds for blackwell, the 5090 will run circles around it when it has enough VRAM (or you have enough 5090 cards to fit everything into VRAM).
32gb for the 5090 vs 128gb for digits might put a nasty cap on unleashing all that power for interesting models.
Several 5090s together would work but then we're talking about multiple times the cost (4x$2000+PC VS $3000)
This will make it possible for you to run models up to 405B parameters, like Llama 3.1 405B at 4bit quant or the Grok-1 314B at 6bit quant.
Who knows, maybe some better models will be released in the future which are better optimized and won't need that much RAM, but it is easier to buy a second 'Digits' in comparison to building a rack with 8xGPUs. For example, if you look at the latest Llama models, Meta states: 'Llama 3.3 70B approaches the performance of Llama 3.1 405B'.
To interfere with Llama3.3-70B-Instruct with ~8k context length (without offloading), you'd need: - Q4 (~44GB): 2x5090; 1x 'Digits' - Q6 (~58GB): 2x5090; 1x 'Digits' - Q8 (~74GB): 3x5090; 1x 'Digits' - FP16 (~144GB): 5x5090; 2x 'Digits'
Let's wait and see which bandwidth it will have.
Speculation has it at ~5XXgb/s.
agreed on the memory.
if I can I'll get a few but I fear they'll sell out immediately
It won't stop crypto and LLM peeps from buying everything (one assumes TDP is proportional too). Gamers not being able to find an affordable option is still a problem.
Used to think about this often because I had a side hobby of building and selling computers for friends and coworkers that wanted to get into gaming, but otherwise had no use for a powerful computer.
For the longest time I could still put together $800-$1000 PC's that could blow consoles away and provide great value for the money.
Now days I almost want to recommend they go back to console gaming. Seeing older ps5's on store shelves hit $349.99 during the holidays really cemented that idea. Its so astronomically expensive for a PC build at the moment unless you can be convinced to buy a gaming laptop on a deep sale.
Consoles have historically not done so well with backwards compatibility (at most one generation). I don't do much console gaming but _I think_ that is changing.
There is also something to be said about catalog portability via something like a Steam Deck.
Personally, I just don't like that its attached to steam. Which is why I can be hesitant to suggest consoles as well now that they have soft killed their physical game options. Unless you go out of your way to get the add-on drive for PS5, etc
Its been nice to see backwards compatibility coming back in modern consoles to some extent with Xbox especially if you have a Series-X with the disc drive.
I killed my steam account with 300+ games just because I didn't see a future where steam would actually let me own the games. Repurchased everything I could on GoG and gave up on games locked to Windows/Mac AppStores, Epic, and Steam. So I'm not exactly fond of hardware attached to that platform, but that doesn't stop someone from just loading it up with games from a service like GoG and running them thru steam or Heroic Launcher.
2024 took some massive leaps forward with getting a proton-like experience without steam and that gives me a lot of hope for future progress on Linux gaming.
Just out of interest, if I bought a PS5 with the drive, and a physical game, would that work forever (just for single-player games)?
Like you, I like to own the things I pay for, so it's a non-starter for me if it doesn't.
We'll have to see how much they'll charge for these cards this time, but I feel like the price bump has been massively exaggerated by people on HN
https://www.nvidia.com/en-us/geforce/graphics-cards/40-serie...
The cards were then sold around that ballpark you said, but that was because the shops could and they didn't say no to more profit.
We will have to wait to see what arbitrary prices the shops will set this time.
If they're not just randomly adding 400+ on top, then the card would cost roughly the same.
5070, 5070 Ti, 5080, 5090 to
5000, 5000 Plus, 5000 Pro, 5000 Pro Max.
:O
Source: https://www.nvidia.com/en-us/data-center/technologies/blackw...
If that holds up in the benchmarks, this is a nice jump for a generation. I agree with others that more memory would've been nice, but it's clear Nvidia are trying to segment their SKUs into AI and non-AI models and using RAM to do it.
That might not be such a bad outcome if it means gamers can actually buy GPUs without them being instantly bought by robots like the peak crypto mining era.
Also since they're not coming from the game engine, they don't actually react as the game would, so they don't have advantages in terms of response times that actual frame rate does.
3x the FPS at same cost (ignoring AI cores, encoders, resolutions, etc.) is a decent performance track record. With DLSS enabled the difference is significantly bigger.
* Neural texture stuff - also super exciting, big advancement in rendering, I see this being used a lot (and helps to make up for the meh vram blackwell has)
* Neural material stuff - might be neat, Unreal strata materials will like this, but going to be a while until it gets a good amount of adoption
* Neural shader stuff in general - who knows, we'll see how it pans out
* DLSS upscaling/denoising improvements (all GPUs) - Great! More stable upscaling and denoising is very much welcome
* DLSS framegen and reflex improvements - bleh, ok I guess, reflex especially is going to be very niche
* Hardware itself - lower end a lot cheaper than I expected! Memory bandwidth and VRAM is meh, but the perf itself seems good, newer cores, better SER, good stuff for the most part!
Note that the material/texture/BVH/denoising stuff is all research papers nvidia and others have put out over the last few years, just finally getting production-ized. Neural textures and nanite-like RT is stuff I've been hyped for the past ~2 years.
I'm very tempted to upgrade my 3080 (that I bought used for $600 ~2 years ago) to a 5070 ti.
I'm hoping generative AI models can be used to generate more immersive NPCs.
I would expect something like the 5080 super will have something like 20/24Gb of VRAM. 16Gb just seems wrong for their "target" consumer GPU.
This time around, I will save for the 5090 or just wait for the Ti/Super refreshes.
https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
When was the last time Nvidia made a high end GeForce card use only 2 slots?
(Looks like Nvidia even advertises an "SFF-Ready" label for cards that are small enough: https://www.nvidia.com/en-us/geforce/news/small-form-factor-...)
(But I'm more eyeing the 5080, since 360W is pretty easy to power and cool for most SFF setups.)
Gaming performance has been plateaued for some time now, maybe an 8k monitor wave can revive things
Seemingly NVIDIA is just playing number games, like wow 3352 is a huge leap compared to 1321 right? But how does it really help us in LLMs, diffusion models and so on?
> DLPerf (Deep Learning Performance) - is our own scoring function. It is an approximate estimate of performance for typical deep learning tasks. Currently, DLPerf predicts performance well in terms of iters/second for a few common tasks such as training ResNet50 CNNs. For example, on these tasks, a V100 instance with a DLPerf score of 21 is roughly ~2x faster than a 1080Ti with a DLPerf of 10. [...] Although far from perfect, DLPerf is more useful for predicting performance than TFLops for most tasks.
5090 is 26% higher flops than 4090, at 28% higher power draw, and 25% higher price.
The real jump is 26%, at 28% higher power draw and 25% higher price.
A dud indeed.
2x faster in DLSS. If we look at the 1:1 resolution performance, the increase is likely 1.2x.
The bold claim "5070 is like a 4090 at 549$" is quite different if we factor in that it's basically in DLSS only.
The cat loves laying/basking on it when it’s putting out 1400w in 400w mode though, so I leave it turned up most of the time! (200w for the cpu)
Also, not having to do the environment setup typically required for cloud stuff is a nice bonus.
32 GB VRAM on the highest end GPU seems almost small after running LLMs with 128 GB RAM on the M3 Max, but the speed will most likely more than make up for it. I do wonder when we’ll see bigger jumps in VRAM though, now that the need for running multiple AI models at once seems like a realistic use case (their tech explainers also mentions they already do this for games).
For more of the fast VRAM you would be in Quadro territory.
I like the Llama models personally. Meta aside. Qwen is fairly popular too. There’s a number of flavors you can try out. Ollama is a good starting point to try things quickly. You’re def going to have to tolerate things crashing or not working imo before you understand what your hardware can handle.
PC gamers would say that a modern mid-range card (1440p card) should really have 16GB of vram. So a 5060 or even a 5070 with less than that amount is kind of silly.
One normally uses some ultra texture pack to utilize current gen card's memory fully on many games.
Conversely, this means you can pay less if you need less.
Seems like a win all around.
Their strategy is to sell lower-VRAM cards to consumers with the understanding that they can make more money on their more expensive cards for professionals/business. By doing this, though they're creating a gap in the market that their competitors could fill (in theory).
Of course, this assumes their competitors have half a brain cell (I'm looking at YOU, Intel! For fuck's sake give us a 64GB ARC card already!).
I use Firefox and have an 8Gb card and only encounter problems when I have more than about 125 windows with about 10-20 tabs each.
Yes, I am a tab hoarder.
And yes, I am going to buy a 16Gb card soon. :P
lol okay. "doing it wrong" for a tenth of the cost.
There's a reason large companies are buying H100s and not 4090s. Despite what you guys think, serious ML work isn't done on the consumer cards for many reasons: FP16/FP8 TFLOPS, NVLINK, power consumption, physical space, etc.
I know my 10 GB 3080 ran out of VRAM playing it on Ultra, and i was getting as low as 2 fps because I'm bottlenecked by the PCI-Express bus as it has to constantly page the entire working set of textures and models in and out.
I'm getting a 5090 for that, plus I want to play around with 7B parameter LLMs and don't want to quantize below 8 bits if I can help it.
And that's at 1440p, not even 4K. The resulting stutters are... not pretty.
This isn't like a cutdown die, which is a single piece with disabled functionality...the memory chips are all independent (expensive) pieces soldered on board (the black squares surrounding the GPU core):
https://cdn.mos.cms.futurecdn.net/vLHed8sBw8dX2BKs5QsdJ5-120...
These are monumentally different. You cannot use your computer as an LLM. Its more novelty.
I'm not even sure why people mention these things. Its possible, but no one actually does this out of testing purposes.
It falsely equates Nivida GPUs with Apple CPUs. The winner is Apple.
And yet it just so happens they work effectively the same. I've done research on an RTX 2070 with just 8 GB VRAM. That card consistently met or got close to the performance of a V100 albeit with less vram.
Why indicate people shouldn't use consumer cards? It's dramatically (like 10x-50x) cheaper. Is machine learning only for those who can afford 10k-50k USD workstation GPU's? That's lame and frankly comes across as gate keeping.
Honestly I can't really imagine how a person could reasonably have this stance. Just let folks buy hardware and use it however they want. Sure if may be less than optimal but it's important to remember that not everyone in the world has the money to afford an H100.
Perhaps you can explain some other better reason for why people shouldn't use consumer cards for ML? It's frankly kind of a rude suggestion in the absence of a better explanation.
Which may be true although there are more differences than just VRAM and I assume those market segments have different perceptions of the real value Gamers want it cheaper/faster, institutions want it closer to state of the art, more robust to lengthy workloads (as in year long training sessions), and better support from nvidia. Among other things.
RTX 5090: 32 GB GDDR7, ~1.8 TB/s bandwidth. H100 (SXM5): 80 GB HBM3, ~3+ TB/s bandwidth.
RTX 5090: ~318 TFLOPS in ray tracing, ~3,352 AI TOPS. H100: Optimized for matrix and tensor computations, with ~1,000 TFLOPS for AI workloads (using Tensor Cores).
RTX 5090: 575W, higher for enthusiast-class performance. H100 (PCIe): 350W, efficient for data centers.
RTX 5090: Expected MSRP ~$2,000 (consumer pricing). H100: Pricing starts at ~$15,000–$30,000+ per unit.
BIS demands it to be less than $4800 TOPS \times Bit-Width$, and the most plausible explanation for the number is - 2375 sparse fp4/int4 TOPS, which means 1187.5 dense TOPS for 4 bit, or $4750 TOPS \times Bit-Width$.
They’re not really supposed to either judging by how they priced this. For non AI uses the 5080 is infinitely better positioned
...and also slower than a 4090. Only the 5090 got a gen/gen upgrade in shader counts. Will have to wait for benchmarks of course, but the rest of the 5xxx lineup looks like a dud
The area's geography just isn't conducive to allowing a single brick and mortar store to survive and compete with online retail for costs vs volume; but without a B&M store there's no good way to do physical presence anti-scalper tactics.
I can't even get in a purchase opportunity lottery since AMD / Nvidia don't do that sort of thing for allocating restock quota tickets that could be used as tokens to restock product if a purchase is to the correct shipping address.
I can understand lack of supply, but why can't I go on nvidia.com and buy something the same way I go on apple.com and buy hardware?
I'm looking for GPUs and navigating all these different resellers with wildly different prices and confusing names (on top of the already confusing set of available cards).
It's just not their main business model, it's been that way for many many years at this point. I'm guessing business people have decided that it's not worth it.
Saying that they are "resellers" isn't technically accurate. The 5080 you buy from ASUS will be different than the one you buy from MSI.
Most people don't realize that Nvidia is much more of a software company than a hardware company. CUDA in particular is like 90% of the reason why they are where they are while AMD and Intel struggle to keep up.
Totally agree with the software part. AMD usually designs something in the same ball park as Nvidia, and usually has a better price:performance ratio at many price points. But the software is just too far behind.
But the business software stack was, yes, best in class. But it's not so for the consumer!
I have no experience with PCI-E 5 cables, but I've a PCI-E 4 riser cable from Athena Power that works just fine (and that you can buy right now on Newegg). It doesn't have any special locking mechanism, so I was concerned that it would work its way off of the card or out of the mobo slot... but it has been in place for years now with no problem.
The "away from motherboard expansion card slots feature" isn't particularly uncommon on cases. One case that came up with a quick look around is the Phanteks Enthoo Pro 2. [2] I've seen other case manufacturers include this feature, but couldn't be arsed to spend more than a couple of minutes looking around to find more than one example to link to.
Also, there are a few smaller companies out there that make adapters [3] that will screw into a 140mm fan mounting hole and serve as an "away from motherboard" mounting bracket. You would need to remove any grilles from the mounting hole to make use of this for a graphics card.
[0] https://www.newegg.com/athena-power-8-extension-cable-black/...
[1] https://www.newegg.com/Athena-Power/BrandStore/ID-1849
[2] https://phanteks.com/product/enthoo-pro-2-tg
[3] Really, they're usually just machined metal rectangular donuts... calling them "adapters" makes them sound fancier than they are.
Can't put four 4090s into your PC if every 4090 is 3.5 slots!
Nvidia has internal access to the new card way ahead of time, has aerodynamic and thermodynamic simulators, custom engineered boards full of sensors, plus a team of very talented and well paid engineers for months in order to optimize cooler design.
Meanwhile AIB partners is pretty much kept in the blind until a few months in advance. It is basically impossible for a company like EVGA to exist as they pride themselves in their customer support - the finances just does not make sense.
https://www.electronicdesign.com/technologies/embedded/artic...
Also aren't most of the business cards made by Nvidia directly... or at least Nvidia branded?
Since then, Nvidia is locked in a very strange card war with their board partners, because Nvidia has all the juicy inside details on their own chips which they can just not give the same treatment to their partners, stacking the deck for themselves.
Also, the reason why blowers are bad is because the design can't really take advantage of a whole lot of surface area offered by the fins. There's often zero heat pipes spreading the heat evenly in all directions, allowing a hot spot to form.
it's not worth it.
There is profit in this, but it’s also a whole set of skills that doesn’t really make sense for Nvidia.
You can? Thought this thread was about how they're sold out everywhere.
So scalpers want to make a buck on that.
All there is to it. Whenever demand surpasses supply, someone will try to make money off that difference. Unfortunately for consumers, that means scalpers use bots to clean out retail stores, and then flip them to consumers.
So nvidia wouldn't have the connections or skillset to do budget manufacturing of low-cost holder boards the way ASUS or EVGA does. Plus with so many competitors angling to use the same nvidia GPU chips, nvidia collects all the margin regardless.
1. Many people knew the new series of nvidia cards was about to be announced, and nobody wanted to get stuck with a big stock of previous-generation cards. So most reputable retailers are just sold out.
2. With lots of places sold out, some scalpers have realised they can charge big markups. Places like Amazon and Ebay don't mind if marketplace sellers charge $3000 for a $1500-list-price GPU.
3. For various reasons, although nvidia makes and sells some "founder edition" the vast majority of cards are made by other companies. Sometimes they'll do 'added value' things like adding RGB LEDs and factory overclocking, leading to a 10% price spread for cards with the same chip.
4. nvidia's product lineup is just very confusing. Several product lines (consumer, workstation, data centre) times several product generations (Turing, Ampere, Ada Lovelace) times several vram/performance mixes (24GB, 16GB, 12GB, 8GB) plus variants (Super, Ti) times desktop and laptop versions. That's a lot of different models!
nvidia also don't particularly want it to be easy for you to compare performance across product classes or generations. Workstation and server cards don't even have a list price, you can only get them by buying a workstation or server from an approved vendor.
Also nvidia don't tend to update their marketing material when products are surpassed, so if you look up their flagship from three generations ago it'll still say it offers unsurpassed performance for the most demanding, cutting-edge applications.
https://www.techpowerup.com/gpu-specs/rtx-6000-ada-generatio...
I'm also trying to tie together different hardware specs to model performance, whether that's training or inference. Like how does memory, VRAM, memory bandwidth, GPU cores, etc. all play into this. Know of any good resources? Oddly enough I might be best off asking an LLM.
I have both 4090 (workstation) and 7900XT (to play some games) and I would say that 7900XT was rock solid for me for the last year (I purchased it in Dec 2023).
It is an outdated claim.
Good for you though.
I just upgraded from a 2080 Ti I had gotten just a few weeks into the earliest COVID lockdowns because I was tired of waiting constantly for the next generation.
https://howmuch.one/product/average-nvidia-geforce-rtx-3070-...
Also also, AMD has pretty much thrown in the towel at competing for high end gaming GPUs already.
I miss when high-end GPUs were $300-400, and you could get something reasonable for $100-200. I guess that's just integrated graphics these days.
The most I've ever spent on a GPU is ~$300, and I don't really see that changing anytime soon, so it'll be a long time before I'll even consider one of these cards.
An older 3060 12GB is also a better option than the B580. It runs around $280, and has much better compatibility (and, likely, better performance).
What I'd love to see on all of these are specs on idle power. I don't mind the 5090 approaching a gigawatt peak, but I want to know what it's doing the rest of the time sitting under my desk when I just have a few windows open and am typing a document.
That time is 25 years ago though, i think the Geforce DDR is the last high end card to fit this price bracket. While cards have gotten a lot more expensive those $300 high end cards should be around $600 now. And $200-400 for low end still exists.
I'm planning to upgrade (prob to a mid-end) as my 5 year old computer is starting to show it's age, and with the new GPUs releasing this might be a good time.
Translation: No significant actual upgrade.
Sounds like we're continuing the trend of newer generations being beaten on fps/$ by the previous generations while hardly pushing the envelope at the top end.
A 3090 is $1000 right now.
I've heard this twice today so curious why it's being mentioned so often.
Nvidia has done that in the past already (see PhysX).
DCS World?
So why should we consider to buy a GPU at twice the price when it has barely improved rasterization performance? An artificially generation-locked feature anyone with good vision/perception despises isn't going to win us over.
I've found it an amazing balance between quality and performance (ultra everything with quality DLSS looks and run way better than, say, medium without DLSS). But I also don't have great vision, lol.
It's like BMW comparing new M5 model to the previous gen M5 model, while previous gen is on the regular 95 octane, and new gen is on some nitromethane boosted custom fuel. With no information how fast the new car is on a regular fuel.
Does normal gamers actually notice any difference on some normal 4k low latency monitors/tvs? I mean any form of extra lag, screen tearing etc.
Seems like we're now in the Intel CPU stage where they just keep increasing the TDP to squeeze out a few more percentage points, and soon we'll see the same degradation from overheating that they did.
Jensen thinks that "Moore's Law is Dead" and it's just time to rest and vest with regards to GPUs. This is the same attitude that Intel adopted 2013-2024.
Otherwise you could just duplicate every frame 100 times and run at 10k fps
Or hell just generate a million black frames every second, a frames a frame right
And obviously false with DLSS.
Not really worth it if you can get a 5090 for $1,999
Certainly worth paying +$1k if you are doing anything that requires GPU power (hash cracking with hashcat for example)
3090 - 350W
3090 Ti - 450W
4090 - 450W
5090 - 575W
3x3090 (1050W) is less than 2x5090 (1150W), plus you get 72GB of VRAM instead of 64GB, if you can find a motherboard that supports 3 massive cards or good enough risers (apparently near impossible?).
I do a lot of training of encoders, multimodal, and vision models, which are typically small enough to fit on a single GPU; multiple GPUs enables data parallelism, where the data is spread to an independent copy of each model.
Occasionally fine-tuning large models and need to use model-parallelism, where the model is split across GPUs. This is also necessary for inference of the really big models, as well.
But most tooling for training/inference of all kinds of models supports using multiple cards pretty easily.
But it seems more aimed at inference from what I’ve read?
Though I think I've been able to max out my M2 when using the MacBook's integrated memory with MLX, so maybe that won't be an issue.
https://www.hc34.hotchips.org/assets/program/conference/day2...
[1] https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwe...
[2] https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
TOPS means Tera Operations Per Second.
Petaflops means Peta Floating Point Operations Per Second.
... which, at least to my uneducated mind here, doesn't sound comparable.
1. That's used for AI, so it's plausibly what they mean by "AI OPS"
2. It's generally a safe bet that the marketing numbers NVIDIA gives you is going to be for the fastest operations on the computers, and that those are the same for both computers when they're based on the same architecture.
Other than that, Terra is 10^12, Peta is 10^15, so 3352 Tera ops is 3.352 Peta ops and so on.
More energy means more power consumption, more heat in my room, you can't escape thermodynamics. I have a small home office, it's 6 square meters, during summer energy draw in my room makes a gigantic difference in temperature.
I have no intention of drawing more than a total 400w top while gaming and I prefer compromising on lowering settings.
Energy consumption can't keep increasing over and over forever.
I can even understand it on flagships, they meant for enthusiasts, but all the tiers have been ballooning in energy consumption.
In the US the limiting factor is the 15A/20A circuits which will give you at most 2000W. So if the performance is double but it uses only 30% more power, that seems like a worthwhile tradeoff.
But at some point, that ends when you hit a max power that prevents people from running a 200W CPU and other appliances on the same circuit without tripping a breaker.
I'm currently running a 150 watt GPU, and the 5070 has a 250 TDP. You are correct. I could get a 5070 and down volt it to work in 150ish range e.g. and get almost the same performance (at least not significantly different to notice in game).
But I think you're missing the wider point of my complain: it's been from Maxwell that Nvidia hasn't produced major updates on the power consumption side of their architecture.
Simply making bigger and denser chips on better nodes while keeping to increase the power draw and slapping DLSS4 is not really an evolution, it's laziness and milking the users.
On top of that: the performance benefits we're talking about are really using DLSS4, which is artificially limited to the latest gen. I don't expect raw performance of this gen to exceed a 20% bump to the previous one when DLSS is off.
Is this true or is it just that the default configuration draws a crazy amount of power? I wouldn't imagine running a 5090 downvolted to 75W is useful, but also I would like to see someone test it against an actual 75W card. I've definitely read that you can get 70% of the performance for 50% of the power if you downvolt cards, and it would be interesting to see an analysis of what the sweet spot is for different cards.
If you're undervolting a GPU because it doesn't have a setting for "efficiency mode" in the driver, that's just kinda sad.
There may be times when you do want the performance over efficiency.
I can confirm you that downvolting can get you the same tier of performance (-10%, which by the way is 3 fps when you're making 3 and 10 when you're making 100, negligible) by cutting power consumption by a lot, how much is that a lot depends on the specific gpu. On the 4090 you can get 90% of the performance at half the power draw, lower tier car have smaller gain/benefits ratios.
I'm not buying GPUs that expensive nor energy consuming, no chance.
In any case I think Maxwell/Pascal efficiency won't be seen anymore, with those RT cores you get more energy draw, can't get around that.
I've wanted to upgrade but overall I'm more concerned about power consumption than raw total performance and each successive generation of GPUs from nVidia seems to be going the wrong direction.
That's not the end of the world for me if I move to a 5070 ti and you are quite correct that I can downclock/undervolt to keep a handle on power consumption. The price makes it a bit of a hard pill to swallow though.
I upgrade GPUs then keep launching League of Legends and other games that really don't need much power :)
I built a gaming PC aiming to last 8-10 years. I spent $$$ on MO-RA3 radiator for water cooling loop.
My view:
1. a gaming PC is almost always plugged into a wall powerpoint
2. loudest voices in the market always want "MOAR POWA!!!"
1. + 2. = gaming PC will evolve until it takes up the max wattage a powerpoint can deliver.
For the future: "split system aircon" built into your gaming PC.
Lots of games that are fine on Intel Integrated graphics out there.
Unfortunately, when training on a desktop it's _relatively_ continuous power draw, and can go on for days. :/
And good point on training. I don't know what use cases would be supported by a battery, but there's a marketable one I am sure we will hear about it.
You’re right that a large enough capacitor could do that, and I’ve worked with high voltage supercapacitor systems which can provide tens of watts for minutes, but the cost is so high that lithium batteries typically make more sense.
I guess PC power supplies need to start adopting this standard.
You could get an electrician to install a different outlet like a NEMA 6-20 (I actually know someone who did this) or a European outlet, but it's not as simple as installing more appliance circuits, and you'll be paying extra for power cables either way.
If you have a spare 14-30 and don't want to pay an electrician, you could DIY a single-phase 240v circuit with another center tap transformer, though I wouldn't be brave enough to even attempt this, much less connect a $2k GPU to it.
If someone made a PC power supply designed to plug into a NEMA 14-50 you could run a lot of GPUs! And generate a lot of heat!
https://www.amazon.com/IronBox-Electric-Connector-Power-Cord...
https://www.amazon.com/14-50P-6-15R-Adapter-Adaptor-Charger/...
As long as the PSU has proper overcurrent protection, you could get away with saying it is designed for this. I suspect you meant designed for higher power draw rather than merely designed to be able to be plugged into the receptacle, but your remark was ambiguous.
Usually, the way people do things to get higher power draw is that they have a power distribution unit that provides C14 receptacles and plugs into a high power outlet like this:
https://www.apc.com/us/en/product/APDU9981EU3/apc-rack-pdu-9...
Then they plug multiple power supplies into it. They are actually able to use the full available AC power this way.
A (small) problem with scaling PSUs to the 50A (40A continuous) that NEMA 14-50 provides is that there is no standard IEC connector for it as far as I know. The common C13/C14 connectors are limited to 10A. The highest is C19/C20 for 16A, which is used by the following:
https://seasonic.com/atx3-prime-px-2200/
https://seasonic.com/prime-tx/
If I read the specification sheets correctly, the first one is exclusively for 200-240VAC while the second one will go to 1600W off 120V, which is permitted by NEMA 5-15 as long as it is not a continuous load.
There is not much demand for higher rated PSUs in the ATX form factor most here would want, but companies without brand names appear to make ones that go up to 3.6kW:
https://www.amazon.com/Supply-Bitcoin-Miners-Mining-180-240V...
As for even higher power ratings, there are companies that make them in non-standard form factors if you must have them. Here is one example:
https://www.infineon.com/cms/en/product/promopages/AI-PSU/#1...
But when people speak of voltages, they usually mean what you get from a typical socket.
That said, a typical socket likely varies more in the U.S. than in Europe since anything that is high draw in the U.S. gets 240VAC while Europe's 220VAC likely suffices for that. I actually have experimented with running some of my computers off 240VAC. It was actually better than 120VAC since the AC to DC conversion is more efficient when stepping down from 240VAC. Sadly, 240VAC UPS units are pricy, so I terminated that in favor of 120VAC until I find a deal on a 240VAC UPS unit.
For consumers, they do not care.
PCIe Gen 4 dictates a tighter tolerance on signalling to achieve a faster bus speed, and it took quite a good amount of time for good quality Gen 4 risers to come to market. I have zero doubt in my mind that Gen 5 steps that up even further making the product design just that much harder.
> gen 5 cabling
But NVIDIA is claiming that the 5070 is equivalent to the 4090, so maybe they’re expecting you to wait a generation and get the lower card if you care about TDP? Although I suspect that equivalence only applies to gaming; probably for ML you’d still need the higher-tier card.
If the printer causes your UPS to trip when merely sharing the circuit, imagine the impact to the semiconductors and other active elements when connected as a protected load.
I think it's this one https://youtu.be/olfgrLqtXEo
[0] https://www.nvidia.com/en-us/geforce/news/dlss4-multi-frame-...
But, the advantage is that you can load a much more complex model easily (24GB vs 32GB is much easier since 24GB is just barely around 70B parameters).
(Which, in my opinion, was a contributing factor why VR pc gaming didn't take of when better VR headsets arrived just around that point.)
If mining is only profitable after holding, it wasn't profitable. Because then you could have spent less money to just buy the coins instead of mining them yourself, and held them afterwards.
(with the suggested 1000 W PSU for the current gen, it's quite conceivable that at this rate of increase soon we'll run into the maximum of around 1600 W from a typical 110 V outlet on a 15 A circuit)
It doesn't matter if that's through software or hardware improvements.
This is the same thing they did with the RTX 4000 series. More fake frames, less GPU horsepower, "Moore's Law is Dead", Jensen wrings his hands, "Nothing I can do! Moore's Law is Dead!" which is how Intel has been slacking since 2013.
The 5090 just has way more CUDA cores and uses proportionally more power compared to the 4090, when going by CUDA core comparisons and clock speed alone.
All of the "massive gains" were comparing DLSS and other optimization strategies to standard hardware rendering.
Something tells me Nvidia made next to no gains for this generation.
> Something tells me Nvidia made next to no gains for this generation.
Sounds to me like they made "massive gains". In the end, what matters to gamers is
1. Do my games look good? 2. Do my games run well?
If I can go from 45 FPS to 120 FPS and the quality is still there, I don't care if it's because of frame generation and neural upscaling and so on. I'm not going to be upset that it's not lovingly rasterized pixel by pixel if I'm getting the same results (or better, in some cases) from DLSS.
To say that Nvidia made no gains this generation makes no sense when they've apparently figured out how to deliver better results to users for less money.
Though some CRT emulation techniques require more than that to scale realistic 'flickering' effects.
Just moving my mouse around, I can tell the difference between 60 and 144 fps when I move my pointer from my main monitor (144 hz) to my second monitor (60 hz).
Watching text scroll is noticeably smoother and with less eye tracking motion blur at 144 hz versus 60.
An object moving across my screen at 144 fps will travel fewer pixels per frame than 60 fps. This gain in motion fluidity is noticeable.
... now I wonder ... Do DLSS models take mouse movements and keypresses into account?
"MPEG uses motion vectors to efficiently compress video data by identifying and describing the movement of objects between frames, allowing the encoder to predict pixel values in the current frame based on information from previous frames, significantly reducing the amount of data needed to represent the video sequence"
By the way, I thought these AI things served to increase resolution, not frame rate. Why doesn't it work that way?
Making better looking individual frames and benchmarks for worse gameplay experiences is an old tradition for these GPU makers.
A game running at 60 fps averages around ~16 ms and good human reaction times don’t go much below 200ms.
Users who “notice” individual frames are usually noticing when a single frame is lagging for the length of several frames at the average rate. They aren’t noticing anything within the span of an average frame lifetime
if you added 200ms latency to your mouse inputs, you’d throw your computer out the of the window pretty quickly.
30 FPS is 33.33333 MS 60 FPS is 16.66666 MS 90 FPS is 11.11111 MS 120 FPS is 8.333333 MS 140 FPS is 7.142857 MS 144 FPS is 6.944444 MS 180 FPS is 5.555555 MS 240 FPS is 4.166666 MS
Going from 30fps to 120fps is 25ms which is totally 100% noticeable even for layman (I actually tested this with my girlfriend, she could tell between 60fps and 120fps as well), but these generated frames from DLSS don't help with this latency _at all_.
Although the nVidia Reflex technology can help with this kind of latency in some situations in some non quantifiable ways.
That's just it isn't. This stuff isn't "only detectable by profession competitive gamers" like many are proposing. It's instantly noticeable to the average gamer.
I use DLSS type tech, but you lose a lot of fine details with it. Far away text looks blurry, textures aren’t as rich, and lines between individual models lose their sharpness.
Also, if you’re spending $2000 for a toy you are allowed to have high standards.
Unfortunately, there are no 4K displays with 200+ DPI on the market. If you want high DPI you either need pick glossy 5k@27" or go to 6k/8k.
a 27" 1080p screen has 37ppd at 2 feet.
a 42" 4k screen has 51ppd at 2 feet.
a 27" 8k screen has 147ppd at 2 feet which is just absurd.
You have to get to 6 inches for the PPD to be 61
I know I'll be gunning for the 42" 8K's whenever they actually reach a decent market price. Sigh, still too many years away.
I cannot brag with sharp eyesight, but I can definitely tell difference between 4k@27" at 60cm = 73PPD and 5k@27" at 60cm = 97PPD. Text is much crisper on the latter.
I've also compared Dell 8k to 6k. There is a still a difference, but it is not that big.
You must have exceptional eyesight.
There are 4k 24" monitors (almost 200 DPI) and 4k 18.5" portable monitors (more than 200 DPI) you can buy nowadays
Cause it ain't about the gameplay or the usefulness. It's all about that big dick energy.
8k traditional rendering at 144Hz is a lot of pixels. We are seeing a 25%/3 years improvement cycle on traditional rendering at this point, and we need about 8x improvement in current performance to get there.
2040 is definitely possible, but certainly not guaranteed.
Makes you wonder how far ahead displays will be in 2040. I can imagine display prices falling in price and increasing in quality to the point where many homes just have displays paneled around the walls instead of paint.
If we're moving towards real time tracing compute is going to always be a limitting factor, as it was in the days of pre rendering. Granted currently raster techniques can simulate ray trace pretty well in many scenarios and looks much better in motion, IMO that's more limitation of real time ray trace. There's a bunch of image quality improvements beyond raster to be gained if enough compute is throw at ray tracing, i think a lot of dlss / frame generation goal is basically to offload more cpu to generate higher IQ hero frames while filling in blanks.
Sure, but compute is a limiting factor.
DLSS might not be as good as pure unlimited pathtracing, but for a given budget it might be better than rasterization alone.
I’m saying that it’s different enough that you shouldn’t compare the two.
- Data Center: Third-quarter revenue was a record $30.8 billion
- Gaming and AI PC: Third-quarter Gaming revenue was $3.3 billion
If the gains are for only 10% of your customers, I would put this closer to the "next to no gains" rather than the "massive gains".
i d like to point you to r/FuckTAA
>Do my games run well
if the internal logic is still in sub 120 hz and it is a twichy game, then no
People who keep giving intel endless shit are probably very young and don't remember how innovative Intel was in the 90s and 00s. USB, PCI-Express, Thunderbolt, etc., all Intel inventions, plus involvement in Wifi and wireless telecom standards. They are guilty of anti competitive practices and complacency in the last years but their innovations weren't just node shrinks.
Intel’s strategy after it adopted EM64T (Intel’s NIH syndrome name for amd64) from AMD could be summarized as “increase realizable parallelism through more transistors and add more CISC instructions to do key work loads faster”. AVX512 was that strategy’s zenith and it was a disaster for them since they had to cut clock speeds when AVX-512 operations ran while AMD was able to implement them without any apparent loss in clock speed.
You might consider the more recent introduction of E cores to be an innovation, but that was a copy of ARM’s big.little concept. The motivation was not so much to save power as it was for ARM but to try to get more parallelism out of fewer transistors since their process advantage was gone and the AVX-512 fiasco had showed that they needed a new strategy to stay competitive. Unfortunately for Intel, it was not enough to keep them competitive.
Interestingly, leaks from Intel indicate that Intel had a new innovation in development called Royal Core, but Pat Gelsinger cancelled it last year before he “resigned”. The cancellation reportedly lead to Intel’s Oregon design team resigning.
AMD up until zen 5 didn't have a full AVX-512 support so not exactly a fair comparison. Intel designs don't suffer from that issue AFAIU for couple of iterations already.
But I agree with you, I always thought and I still do that Intel has a very strong CPU core design but where AMD changed the name of the game IMHO is the LLC cache design. Hitting as much as ~twice lower LLC latency is insane. To hide this big of a difference in latency, Intel has to pack larger L2+LLC cache sizes.
Since LLC+CCX design scales so well AMD is also able to pack ~50% more cores per die, something Intel can't achieve even with the latest Granite Rapids design.
These two reasons let alone are big things for data center workloads so I really wonder how Intel is going to battle that.
https://en.wikipedia.org/wiki/AVX-512#CPUs_with_AVX-512
It also took either 4 or 6 years for Intel to fix its downclocking issues, depending on whether you count Rocket Lake as fixing a problem that started in enterprise CPUs, or require Sapphire Rapids to have been released to consider the problem fixed:
https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Dow...
(1) drive 2x AVX-512 computations
(2) handle 2x AVX-512 memory loads + 1x AVX-512 memory store
The latter makes a big impact wrt available memory BW per core, at least when it comes to the workloads whose data is readily available in L0 cache. Intel in these experiments is crushing AMD by a large factor simply because their memory controller design is able to sustain 2x64B loads + 1x64B stores in the same clock. E.g. 642 GB/s (Golden Cove) vs 334 GB/s (zen4) - this is a big difference and this is something that Intel had for ~10 years whereas AMD was able to solve this with zen5, basically only with the end of 2024.
Former one limits the theoretical FLOPS/core capabilities since single AVX-512 FMA operation in zen4 is implemented as two AVX2 uops occupying both FMA slots per clock. This is also big and, again, this is something where Intel had a lead up until zen5.
Wrt downclocking issues, they had a substantial impact with Skylake implementation but with Ice Lake this was a solved issue and this was in 2019. I'm cool with having ~97% of max freq budget available with heavy AVX-512 workloads.
OTOH AMD is also very thin with this sort of information and some experiments show that turbo boost clock frequency on zen4 lowers from one CCD to another CCD [1]. It seems like zen5 exhibits similar behavior [2].
So, although AMD is displaying continuous innovation for the past several years this is only because they had a lot to improve. Their pre-zen (2017) designs were basically crap and could not compete with Intel who OTOH had a very strong CPU design for decades.
I think that the biggest difference in CPU core design really is in the memory controller - this is something Intel will need to find an answer to since AMD matched all the Intel strengths that it was lacking with zen5.
[1] https://chipsandcheese.com/p/amds-zen-4-part-3-system-level-...
[2] https://chipsandcheese.com/p/amds-ryzen-9950x-zen-5-on-deskt...
https://www.ixpug.org/images/docs/ISC23/McCalpin_SPR_BW_limi...
https://www.ixpug.org/images/docs/ISC23/McCalpin_SPR_BW_limi...
Your 642 GB/s figure should be for a single Golden Cove core, and it should only take 3 Golden Cove cores to saturate the 1.6 TB/sec HBM2e in Xeon Max, yet internal bottlenecks prevented 56 Golden Cove cores from reaching the 642 GB/s read bandwidth you predicted a single core could reach when measured. Peak read bandwidth was 590 GB/sec when all 56 cores were reading.
According to the slides, peak read bandwidth for a single Golden Cove core in the sapphire rapids CPU that they tested is theoretically 23.6GB/sec and was measured at 22GB/sec.
Chips and Cheese did read bandwidth measurements on a non-HBM2e version of sapphire rapids:
https://chipsandcheese.com/p/a-peek-at-sapphire-rapids
They do not give an exact figure for multithreaded L3 cache bandwidth, but looking at their chart, it is around what TACC measured for HBM2e. For single threaded reads, it is about 32 GB/sec from L3 cache, which is not much better than it was for reads from HBM2e and is presumably the effect of lower latencies for L3 cache. The Chips and Cheese chart also shows that Sapphire Rapids reaches around 450 GB/sec single threaded read bandwidth for L1 cache. That is also significantly below your 642 GB/sec prediction.
The 450 GB/sec bandwidth out of L1 cache is likely a side effect of the low latency L1 accesses, which is the real purpose of L1 cache. Reaching that level of bandwidth out of L1 cache is not likely to be very useful, since bandwidth limited operations will operate on far bigger amounts of memory than fit in cache, especially L1 cache. When L1 cache bandwidth does count, the speed boost will last a maximum of about 180ns, which is negligible.
What bandwidth CPU cores should be able to get based on loads/stores per clock and what bandwidth they actually get are rarely ever in agreement. The difference is often called the Von Neumann bottleneck.
Intel's iGPUs were low end. Battlemage looks firmly mid-range at the moment with between 4060/4070 performance in a lot of cases.
https://www.youtube.com/watch?v=ghT7G_9xyDU
we do see power requirements on the high end parts every generation, but that may be to maintain the desired SKU price points. there's clearly some major perf/watt improvements if you zoom out. idk how much is arch vs node, but they have plenty of room to dissipate more power over bigger dies if needed for the high end.
None of this is magic. None of it is even particularly hard. There's no reason for any of it to get stuck. (Intel's problem was letting the beancounters delay EUV - no reason to expect there to be a similar mis-step from Nvidia.)
The intel problem was that their foundries couldn't improve the die size while the other foundries kept improving theirs. But technically nvidia can switch foundry if another one proves better than TSMC even though that doesn't seem likely (at least without a major breakthrough not capitalized by ASML).
Isn't not being kept a secret, its being openly discussed that they need to leverage AI for better gaming performance.
If you can use AI to go from 40fps to 120fps with near identical quality, then that's still an improvement
I've been using DLSS for FPS and racing games since I got my 3080 on launch and it works perfectly fine.
Frame gen might be a different story and Nvidia are releasing improvements, but DLSS isn't terrible at all.
So the biggest benefit is PCIe 5 and the faster/more memory (credit going to Micron).
This is one of the worst generational upgrades. They’re doing it to keep profits in the data center business.
Going from 60 to 120fps is cool. Going from 120fps to 240fps is in the realm of diminishing returns, especially because the added latency makes it a non starter for fast paced multiplayer games.
12GB VRAM for over $500 is an absolute travesty. Even today cards with 12GB struggle in some games. 16GB is fine right now, but I'm pretty certain it's going to be an issue in a few years and is kind of insane at $1000. The amount of VRAM should really be double of what it is across the board.
You can try out pretty much all GPUs on a cloud provider these days. Do it.
VRAM is important for maxing out your batch size. It might make your training go faster, but other hardware matters too.
How much having more VRAM speeds things up also depends on your training code. If your next batch isn’t ready by the time one is finished training, fix that first.
Coil whine is noticeable on my machine. I can hear when the model is training/next batch is loading.
Don’t bother with the founder’s edition.
> Don’t bother with the founder’s edition.
Why?
It seems obvious to me that even NVIDIA knows that 5090s and 4090s are used more for AI Workloads than gaming. In my company, every PC has 2 4090s, and 48GB is not enough. 64GB is much better, though I would have preferred if NVIDIA went all in and gave us a 48GB GPU, so that we could have 96GB workstations at this price point without having to spend 6k on an A6000.
Overall I think 5090 is a good addition to the quick experimentation for deep learning market, where all serious training and inference will occur on cloud GPU clusters, but we can still do some experimentation on local compute with the 5090.
it is easy to be carried away with vram size, but keeping in mind that most people with apple silicon (who can enjoy several times more memory) are stuck at inference, while training performance is off the charts through cuda hardware.
the jury is yet to be out on actual ai training performance, but i bet 4090, if sold at 1k or below, would be better value than lower tier 50 series. the "ai tops" of the 50 series is only impressive for the top model, while the rest are either similar or with lower memory bandwidth despite the newer architecture.
i think by now the training is best left on the cloud and overall i'd be happy rather owning a 5070 ti at this rate.
I always end up late to the party and the prices end up being massively inflated - even now I cant seem to buy a 4090 for anywhere close to the RRP.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}